1.基于java注解实现websocket服务器端 1.1需要的类 1.1.1服务终端类 用java注解来监听连接@ServerEndpoint、连接成功@OnOpen、连接失败@OnClose、收到消息等状态@OnMessage
1.1.2配置类 把spring中的ServerEndpointExporter对象注入进来
2.1代码示例 2.1.1 maven配置 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.heima</groupId> <artifactId>ws-demo</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.16.22</version> </dependency> <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-websocket --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-websocket</artifactId> <version>2.7.14</version> </dependency> </dependencies> </project> 2.1.2 WsServerEndpoint类 package com.heima; import lombok.extern.slf4j.Slf4j; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component; import javax.websocket.OnClose; import javax.websocket.OnMessage; import javax.websocket.OnOpen; import javax.websocket.Session; import javax.websocket.server.ServerEndpoint; import java.
如何查看PostgreSQL的版本 要查看 PostgreSQL 的版本,有几种不同的方法可以使用,包括通过命令行和 SQL 查询。
1. 使用命令行 如果你有访问到服务器的命令行,并且 PostgreSQL 的命令行工具已经添加到了系统的 PATH 中,你可以非常简单地检查版本:
示例1 [pg16@test ~]$ postgres --version postgres (PostgreSQL) 16.2 示例2 [pg16@test ~]$ psql --version psql (PostgreSQL) 16.2 这会返回 psql (PostgreSQL 的命令行界面) 的版本,通常这与 PostgreSQL 服务器的版本相匹配。
示例3 [pg16@test ~]$ pg_config |grep VERSION VERSION = PostgreSQL 16.2 2. 使用 SQL 查询 如果你想要通过 SQL 来查询 PostgreSQL 的版本,你可以连接到数据库,并执行以下 SQL 语句:
[pg16@test ~]$ psql -p 5777 psql (16.2) Type "help" for help. postgres=# SELECT version(); version --------------------------------------------------------------------------------------------------------- PostgreSQL 16.
目录
一.简单参数
1. 参数名与形参变量名相同,定义形参可接收参数
2.如果参数名与形参名字不同就会接收不到但是后端是不会报错的,只会赋值为null
二.实体参数
三.数组集合参数
1.数组接收:只需要后端形参的数组名与前端请求参数名字一致就可以了
2.集合接收:请求参数名与形参集合名称相同,且需要@RequestParam 绑定参数关系
四.日期参数 五.Json参数
六.路径参数
一.简单参数 1. 参数名与形参变量名相同,定义形参可接收参数 axios({ url:'http://localhost:8080/user/getPeople?username=hz&password=123456 ', method:'GET' }).then((res)=>{ alert(res.data.data) }) @GetMapping("/getPeople") public Result selectByUserNameAndPassword(String username,String password){ System.out.println("username:"+username +" password:"+password); return Result.success("ok"); } 以下都是方便展示,就直接赋值了,一般都是动态传参。(如果想了解Axios的可以看看这个博主写的Axios各种参选携带方式🔎)
不管是GET请求还是POST 请求 只要请求参数名与后端形参名一致就可以自动接收。
可以看看打印效果:
浏览器返回结果:
2.如果参数名与形参名字不同就会接收不到但是后端是不会报错的,只会赋值为null 这个时候如果需要 使用Sprngboot 提供的注解 @RequestParam 来完成映射
axios({ url:'http://localhost:8080/user/getPeople?name=hz&password=123456 ', method:'GET' }).then((res)=>{ alert(res.data.data) }) @GetMapping("/getPeople") public Result selectByUserNameAndPassword(@RequestParam(required = false, name = "name") String username,String password){ System.out.println("username:"+username +" password:"+password); return Result.
2024 年 4 月 18 日,Meta开源了 Llama 3 大模型,把 AI 的门槛降低到了最低,这是人工智能领域的一个重要飞跃。我们个人也可以部署大模型了,这简直就是给个人开发者发了个大红包!Llama 3 模型有不同的参数版本,本文主要分享我在个人笔记本电脑是部署 8B 参数过程和编写客户端,让我们大家都参与进来,推动 AI 应用更上一层楼……
本文Llama 3 8B客户端源代码地址:https://gitee.com/obullxl/PythonCS/tree/master/Llama-3-8B
选择 Llama 3 模型版本(8B,80 亿参数) 特别注意: Meta 虽然开源了 Llama 3 大模型,但是每个版本都有 Meta 的许可协议,建议大家在接受使用这些模型所需的条款之前仔细阅读。
Llama 3 模型版本有几个,我们主要关注 80 亿参数(Llama 3 8B)和 700 亿参数(Llama 3 70B)这两个版本。它们对电脑系统配置有不同的要求,主要计算资源(即:CPU/GPU)和内存来存储和处理模型权重:
Llama 3 8B 版本:对于 80 亿参数的模型,建议至少 4 核 CPU,至少 16GB 内存(推荐 32GB 或更高),以确保模型加载和运行过程中的流畅性;模型文件大小 5 GB 左右,磁盘空间有 10GB 足够了;GPU 是可选的,它可以显著提高推理速度
Llama 3 70B 版本:对于 700 亿参数的模型,CPU 要求显著提高(建议 16 核以上),至少需要 64GB 内存(推荐 128GB 或更高),模型在推理时会占用大量的内存资源;模型文件超过 20GB,远超 8B 版本;强烈推荐使用高端 GPU,以实现有效加速
目录
1.概述
2.数据模型
3.API
4.架构
5.一个完整的读写过程
6.如何查找到要的tablet
7.LSM树
1.概述 本文是作者阅读完bigtable论文后对bigtable进行的一个梳理,只涉及核心概念不涉及具体实操,具体实操会在后续的文章中推出。
GFS的出现虽然解决了海量数据的存储问题,但是还是存在一个问题就是如果我存放的数据是结构化的,对结构化数据的使用往往是希望如关系型数据库一样,进行复杂的数据操作的。但是GFS并没有支持基于特定属性(如行键、列名、时间戳)的高效查询、更新、聚合等操作。自然就需要大数据版本的关系型数据库,这就是分布式数据库。
BigTable 是由 Google 开发的一款分布式数据存储系统,专为管理大规模结构化数据而设计,同GFS一样,bigtable是基于Google的具体业务需求而诞生的。
Google最核心的搜索业务,其会用爬虫的方式在整个互联网上爬取网页的信息然后存储起来供搜索引擎使用,也就是要存储海量的web索引。除此之外,Google还有Google Maps(地图)、Gmail(邮件)等应用也需要对海量结构化数据进行高效的查询、更新、聚合等操作。
bigtable基于GFS而来的,底层是用的GFS来进行数据存储。
BigTable 最初的概念和技术细节在 2006 年由 Google 研究人员发表的一篇同名论文《Bigtable: A Distributed Storage System for Structured Data》中公开。这篇论文详细阐述了 BigTable 的设计理念、数据模型、架构和实现细节,对后续的大数据存储技术产生了深远影响。
前面已经说过了bigtable在业务场景中要满足的需求,所以其设计目标总结起来无非就是:
能扛住海量数据
能灵活进行数据操作(增删改查)
能抗住海量数据:
能抗住海量数据无非就要办成两件事:
是能存海量数据
能高效的对海量数据进行读写
要存海量数据自然要有良好的伸缩性,能轻松的进行节点扩展,能支持TB甚至PB级别的数据存储,要有高可靠性,要进行高性能的海量数据的读写其实就要能进行并发的读写。这些要求谁能满足?GFS就能满足,所以bigtable底层就是用GFS来存储数据的。
能灵活进行数据操作:
能对海量数据进行灵活的操作(增删改查)是bigtable的核心诉求。由于海量数据其实是交给GFS来扛的,所以前面的一点bigtable其实是不需要关心的,它要关心的是怎样用一个中间层来在GFS上面实现对数据进行灵活操作。在这个中间层里bigtable用了一套巧妙的数据组织逻辑来进行数据管理,从而实现了核心诉求。
bigtable采用一种基于行键(row key)、列族(column family)和时间戳(timestamp)的多维数据模型,允许用户以高效、灵活的方式组织和访问数据。
2.数据模型 bigtable中一条数据的数据模型(格式)如下:
(row:string,column:string,time:int64)->string 这样设计数据模型,将整行打散为单列,是为了实现数据的灵活操作,bigtable的核心诉求本来就是为了尽量实现数据的灵活操作,这样打散可以在更新的时候避免操作整个行(行数据还是蛮大的,毕竟在大数据的业务场景下逻辑表基本都是大表),而是精确的操作单个列,性能更好。
举个谷歌的业务场景的例子:
爬虫会爬回来的web索引以供搜索引擎使用,这些web索引对应的内容里,可能会经常变的也就是网站的首页,其它很少会变,精确的更新就显得很有价值了。
那么为什么会有时间戳喃?因为Google面对的业务数据大量都是有时序概念的,如爬虫爬回来的web索引,网页的内容是会随着时间改变的,除此之外地图邮件等数据也是有时序属性的。
以CSDN首页为例:
row:作者名
column:头像、简介、文章列表、个人成就等
如果我的主页简介改变了,就只需要新加新的简介的那一个KV对,那对新的KV对生成新的时间序列即可。
3.API 由于数据是分布式存储的,所以其实bigtable还是没办法办到像SQL一样灵活的对数据进行操作,其只能尽力的在GFS之上封装出一套完整的增删改查操作。bigtable支持以下类型的API:
建表、删表
单行数据的增删查,以及用删除和增加组合出来的修改效果,只对单行数据的增删具有ACID特性。
范围查询
4.架构 一张大表肯定是不能存在一个服务器上的,而是被分成多份存在多个服务器上,一份就是一个逻辑单位——tablet。bigtable架构中最核心的概念是tablet。存放tablet的节点在bigtable体系中叫做tablet server,一个tablet server中存放多个tablet。bigtable在最底层把数据按照key进行排列后,进行分区,一个分区就是一个tablet,而一个tablet就是GFS中的一个文件。
tablet只是一个逻辑概念,指代特定范围内的数据行。真正干活儿的是memtable和sstable以及下面的GFS。memtable和sstable可以理解为索引,一个tablet对应着一套memtable和sstable。由于大数据中数据是海量的,所以将索引结构存在磁盘,每次对数据的更新(写入、删除)都要去更新磁盘,肯定是扛不住的。所以将索引放在内存中才是明智的,memtable是缓存,可以理解为就是内存中的索引,一个tablet对应着一个memtable,其中记录着当前节点的tablet中的所有数据(key值+数据指针)。为了容错和可靠,memtable每隔一段时间或者到了一定的阈值后会落磁盘进行持久化,持久化为SSTable,一个tablet存在多个SSTable,这样设计的目的是省去了新老sstable合并带来的额外磁盘IO拉低吞吐量,也可以起到数据版本记录的目的。
所以tablet server我们可以理解为长这个样子:
一.什么是环形链表 环形链表是一种链表的尾结点指向头结点或者其他结点的特殊结构。这个就是环形链表的一种:
二.环形链表的判定 2.1具体题目的举例 2.2解题思路 通过快慢指针来判定,一个指针为慢指针一次走一个,一个指针为快指针一次走两个,如果该链表为环形链表,快指针先进入环形,慢指针后进入,该题变为追击问题,则两指针一定会相遇。慢指针刚进入时,两指针的距离,最好的情况是刚好相遇;最坏的情况为相距一个环。我们只用判断两指针是否会相遇,如果链表无环,fast会先走到空。
2.3思路的解释 slow一次走一个,fast指针一次走两个为什么能追上?fast一次走3,4,5~n呢?
为什么会相遇有没有可能一直错过?
2.3.1slow一次走一个,fast指针一次走两个为什么能追上? 假设slow刚进入环时两指针间的距离为N,fast一次走两位,slow一次走一位,则两者的的相对运动距离为1。则fast到slow的距离变化如下:
N--N-1---N---2----N-3-----------0 每追击一次距离减少一个,为0时追上了。
2.3.4fast一次走3,4,5~n呢? 假设slow刚进入环时两指针间的距离为N,fast一次走三位,slow一次走一位,则两者的的相对运动距离为2。则fast到slow的距离变化分为两类(N为奇数和偶数的情况)如下:
1.N为奇数时:N→N-2→N-4→……1→错过了进行新一轮的追击:设这个环形的长度为C,这时两指针的距离为C-1,这时C要分为奇数偶数,分类讨论:
①C为奇数,则C-1为偶数:
C-1→C-3→C-5→……0追到了
②C为偶数,则C-1为奇数:
C-1→C-3→C-5→……1→错过了进行新一轮的追击,同样是该情况。
2.N为偶数时:N→N-2→N-4→……0 追到了
总结:
1.N为偶数时,第一轮就追到了
2.N为奇数时,第一轮追击会错过,两者距离变为C-1
a.C-1为偶数时,第二轮就追击上了。
b.C-1为奇数时,永远追不上。
由上面推理可知fast一次走3,4,5~n情况类似。
同时存在N是奇数C为偶数时永远追不上。
2.3.5 判断相遇是否会一直错过? 假设slow刚进入环时两指针间的距离为N,fast一次走三位,slow一次走一位,则两者的的相对运动距离为2。设从开始到入环的距离为L,当slow刚如环时,slow运动了L,fast运动了
L+X*C+C-N X为fast绕了几圈环。
且fast的移动位移为slow的3倍,可得:
fast=3*slow
L+X*C+C-N=3L
2L=(X+1)*C-N 由这个式子通过数学分析得:2L是偶数
偶数=(X+1)*C-N 如果要让(X+1)*C-N为偶数则:
①N为偶数时,C为偶数
②N为奇数时,C为奇数
由上个分析可知N是奇数C为偶数时永远追不上
我们已经分析了两种情况,N是奇数C为偶数的情况不可能出现,所以一定会相遇。
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ bool hasCycle(struct ListNode *head) { struct ListNode *slow=head; struct ListNode *fast=head; while(fast&&fast->next) { slow=slow->next; fast=fast->next->next; if(fast==slow) { return true; } } return false; } 三.
👨💻个人主页:@开发者-曼亿点
👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅!
👨💻 本文由 曼亿点 原创
👨💻 收录于专栏:PHP程序开发
⭐🅰⭐ — 文章目录 ⭐🅰⭐⭐前言⭐🎶一、AJAX表单验证🎶二、手机与邮箱验证🎶三、将数据写入数据库 🎶(4)模型的查询修改删除操作 结束语🥇 ⭐前言⭐ 在Web开发中,表单是用户与网站进行交互的主要方式之一。然而,用户提交的表单数据需要经过验证,以确保数据的完整性、安全性和合法性。PHP作为一种强大的服务器端脚本语言,提供了丰富的工具和函数来实现表单验证。
本文将介绍如何使用PHP对表单数据进行验证,包括验证必填字段、验证邮箱、验证密码、验证数字等常见场景。我们将探讨各种验证技术和最佳实践,以确保您的表单在用户提交之前可以正确验证并返回友好的错误提示信息。
通过本文的学习,您将掌握PHP表单验证的基础知识,并能够应用这些知识来构建安全可靠的Web应用程序。无论您是初学者还是有一定经验的开发人员,本文都将为您提供有关PHP表单验证的全面指南,帮助您提升Web开发的技能水平。
🎶一、AJAX表单验证 使用WeUI前端UI框架对其项目进行编写,在UI框架中找到一个合适的登录页面,并进行重新的命名。因为表单提交将会进行页面跳转,因此修改表单提交的方式,改为按钮的提交方式。
给手机输入框和邮箱输入框添加oninput事件,oninput事件在输入框的值发展改变时触发。在手机输入框和邮箱输入框中插入错误提示标签,当输入的手机和邮箱不符合规定时,给出相应的提示,让注册用户立即进行修改,提供用户的体验感。
(1)AJAX表单验证代码展示
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <!-- 让网页的宽度自动适应手机屏幕的宽度 --> <meta name="viewport" content="width=device-width,initial-scale=1,user-scalable=0"> <title>用户注册</title> <!-- 引入 本地 css文件 --> <link rel="stylesheet" href="css/weui.css"/> <link rel="stylesheet" href="jquery-confirm/jquery-confirm.css"/> <!-- 引入本地js文件 --> <script src="js/jquery-3.6.1.min.js"></script> <script src="jquery-confirm/jquery-confirm.js"></script> </head> <body> <form class="weui-form" id="reg_form"> <div class="weui-form__text-area"> <h2 class="weui-form__title">用户注册</h2> </div> <div class="
set、map用法详解 1. 关联式容器2. 键值对2.1 :pair2.2:make_pair 3. 树形结构的关联式容器3.1:set构造函数find()erase()insert()count()lower_bound()upper_bound() 3.2:multiset3.3:map构造函数insert()operator[] 3.4:multimap 4. 在Oj中的使用4.1:前K个高频单词4.2:两个数组的交集I 1. 关联式容器 序列式容器:vector、list、deque、forward_list等这些容器统称为序列式容器,底层是线性序列的数据结构,存储的是元素本身。插入方式一般为push。关联式容器:set、map、multiset、multimap等这些容器统称为关联式容器,也是用来存储数据,但存储的是<key,value>结构的键值对,数据检索的效率比序列式容器高。插入方式一般为insert。 2. 键值对 2.1 :pair 概念:用来表示具有一一对应关系的一种结构,这种结构中一般存储两个成员变量key和value,key表示键值,value表示与key对应的信息。eg:英汉词典、单词的个数。
pair中的first为key,second为value。 2.2:make_pair 概念:是一种可用来构造pair类型对象的函数模板。参数x用来初始化pair中第一个元素的值,参数y用来初始化pair中第二个元素的值。make_pair(x, y)返回值为pair<T1, T2>(x, y),为匿名对象。
3. 树形结构的关联式容器 STL中总共有两种不同结构的管理式容器:树形结构和哈希结构。树形结构的关联式容器主要有四种:set、multiset、map、multimap,共同特征:底层为平衡二叉树(红黑树),容器中的元素是有序序列。
3.1:set set是按特定顺序存储唯一元素的容器。使用迭代器遍历set中的元素,进行中序遍历,可以得到一个有序序列。set具有排序+去重的功能。set中元素必须不能重复,可以用set进行去重。set中元素类型为const T,所以set中的元素不能被修改,但可以在容器中插入或者删除他们。set中元素value就是key,所以set在插入元素时,只需要插入value即可,不需要构造键值对。与map、multimap不同,map、multimap中存储的是<key,value>键值对,set中只存储value,但在底层中实际存放的是由<value, value>构成的键值对。在默认情况下,set中仿函数为less,元素是按照小于来比较,元素呈升序进行排序。set在底层使用平衡二叉搜索树(红黑树)来实现,所以set查找某个元素时,时间复杂度为O(logn)。set容器通过key访问单个元素的速度通常比unordered_set容器慢,允许根据顺序直接对子集进行迭代,即:因为set的有序性,当你迭代一个set时,会按照元素被添加到集合中的顺序看到它们。
构造函数 💡set s1;
功能:无参构造。构造空的set。 💡set s2( InputIterator first, InputIterator last ) ;
功能:迭代器区间构造。构造与[first, last)范围一样多元素的对象。 💡set s3(const set& s2) ;
功能:拷贝构造函数。 #pragma once #define _CRT_SECURE_NO_WARNINGS 1 #include<iostream> #include<set> using namespace std; int main() { set<int> s1; //无参构造 //注意set:排序 + 去重 int a[] = { 6, 3, 4, 2, 1, 6, 4, 5, 2}; set<int> s2(a, a + sizeof(a) / sizeof(int)); //迭代器区间构造 set<int> s3(s2); //拷贝构造 auto it = s2.
目录
一、str函数的常见应用场景
二、str函数使用注意事项
三、如何用好str函数?
1、str函数:
1-1、Python:
1-2、VBA:
2、推荐阅读:
个人主页: https://myelsa1024.blog.csdn.net/
一、str函数的常见应用场景 str函数在Python中有着广泛的应用场景,主要用于将非字符串类型的对象转换为字符串类型,常见的应用场景有:
1、数据类型转换:当你需要将一个非字符串类型(如整数、浮点数、列表、元组、字典等)与字符串进行拼接或者需要以字符串的形式展示该对象时,可以使用str()函数。
2、日志记录:在程序运行时,你可能需要记录一些信息以便调试或追踪问题,使用str()函数可以将复杂的对象转换为字符串,然后写入日志文件中。
3、文件操作:当需要将数据写入文件时,通常需要先将数据转换为字符串。
4、网络编程:在网络编程中,发送和接收的数据通常是字节串(bytes),但在处理这些数据之前,可能需要先将它们转换为字符串。
5、数据库操作:在数据库操作中,经常需要将对象序列化为字符串,以便作为查询参数或存储到数据库中。
6、GUI编程:在图形用户界面(GUI)编程中,通常需要将对象的值以字符串的形式显示在标签、按钮或其他控件上。
7、JSON序列化:在将Python对象转换为JSON格式时,通常需要将对象转换为字符串,虽然直接使用json.dumps()更常见,但在某些情况下,你可能需要先使用str()函数将对象转换为字符串。
总之,str()函数在Python中几乎无处不在,是数据处理和交互中不可或缺的工具。
二、str函数使用注意事项 在Python中,str()函数用于将其他数据类型(如整数、浮点数、列表、元组、字典等)转换为字符串类型,然而,在使用str()函数时,需注意以下事项:
1、非标准数据类型:对于自定义的数据类型,Python不会自动知道如何将其转换为字符串,在这种情况下,你需要为该类型实现一个 `__str__()` 方法,该方法应返回一个表示该对象的字符串。
2、嵌套数据结构:当尝试将嵌套的数据结构(如包含其他列表或字典的列表)转换为字符串时,str()函数将返回一个表示该数据结构的字符串,但可能不是人类可读的。例如,列表将显示为[item1, item2, ...],字典将显示为{key1: value1, key2: value2, ...},如果你需要更详细的表示,可能需要使用其他方法(如json.dumps()来处理字典)。
3、编码问题:当处理包含非ASCII字符的字符串时,你需要确保你的代码环境(如文件编码、终端编码等)可以正确处理这些字符,否则,你可能会遇到编码错误或乱码。
4、性能:虽然str()函数通常很快,但如果你在处理大量数据或进行频繁的字符串转换,那么性能可能会成为一个问题,在这种情况下,你可能需要考虑使用其他方法来优化你的代码。
5、返回值:str()函数总是返回一个字符串,无论输入是什么,但是,这个字符串可能并不总是你期望的。例如,如果你期望得到一个表示日期的字符串,但你的输入是一个整数,那么str()函数将返回一个表示该整数的字符串,而不是日期。
6、空值:如果你尝试将None或其他空值(如空列表或空字典)转换为字符串,str()函数将返回一个表示该空值的字符串(如None、[]或 {})。
7、异常处理:尽管str()函数通常不会引发异常,但如果你尝试将其应用于不支持转换为字符串的对象(如文件对象或网络连接),那么可能会引发异常,在这种情况下,你应该使用适当的异常处理机制(如 `try/except` 块)来捕获和处理这些异常。
三、如何用好str函数? 在Python中,str()函数是一个内置函数,用于将其他数据类型转换为字符串。为了用好str()函数,你应遵循以下建议:
1、明确转换目的:在调用str()函数之前,明确你为何需要将数据转换为字符串?是为了打印、日志记录、存储还是其他目的?这将有助于你选择最合适的转换方式。
2、处理自定义对象:如果你的代码中有自定义对象,并且你需要将它们转换为字符串,确保你已经为这些对象定义了`__str__()`方法,这样,当你调用str()函数时,它将返回由`__str__()`方法定义的字符串表示。
3、处理嵌套数据结构:当处理嵌套的数据结构(如列表、元组、字典等)时,str()函数将返回一个表示这些结构的字符串,如果你需要更详细或更易读的输出,可以考虑使用json.dumps()(对于字典和列表)或其他库来格式化输出。
4、处理编码问题:如果你的代码需要处理包含非ASCII字符的字符串,确保你的代码环境(如文件编码、终端编码等)可以正确处理这些字符,这可以通过在文件顶部指定编码(如`# -*- coding: utf-8 -*-`)或在读取和写入文件时使用正确的编码来实现。
5、性能优化:虽然str()函数通常很快,但在处理大量数据或进行频繁的字符串转换时,性能可能会成为问题,在这种情况下,你可以考虑使用其他方法来优化你的代码,如缓存已转换的字符串或避免不必要的转换。
6、处理空值和特殊值:当使用str()函数转换空值(如None、空列表或空字典)时,请注意返回的字符串表示(如None、[]或{}),确保你的代码可以正确处理这些值。
7、异常处理:虽然str()函数通常不会引发异常,但当应用于不支持转换为字符串的对象时,可能会引发异常,使用`try/except`块来捕获和处理这些异常,以确保你的代码可以优雅地处理错误情况。
8、字符串格式化:除了简单的类型转换外,str()函数还可以与字符串格式化结合使用,你可以使用格式化字符串字面值(f-strings,从Python 3.6开始支持)来嵌入变量和表达式,并使用str()函数来转换非字符串值。
9、使用其他字符串方法:一旦你将数据转换为字符串,你就可以使用Python中丰富的字符串方法来处理它,如split()、replace()、upper()、lower()等,这些方法可以帮助你进一步处理和操作字符串数据。
1、str函数: 1-1、Python: # 1.函数:str # 2.功能: # 2-1、用于将整数、浮点数、列表、元组、字典和集合等转换为字符串类型 # 2-2、用于将字节类型转换为字符串类型 # 3.语法: # 3-1、str([object='']) # 3-2、str(object=b''[, encoding='utf-8', errors='strict']) # 4.
文章目录 每日一句正能量前言常用AI工具创新AI应用个人体验分享后记 每日一句正能量 我们在我们的劳动过程中学习思考,劳动的结果,我们认识了世界的奥妙,于是我们就真正来改变生活了。
前言 随着人工智能(AI)技术的快速发展和普及,越来越多的人们开始使用AI工具来帮助解决各种问题和提升工作效率。在这个快节奏的数字化时代,AI工具为我们提供了许多极具吸引力和实用性的解决方案。本文将探讨人们在使用AI工具时最喜欢和认为最好用的工具,并展示AI技术在实际应用中产生的影响。通过这些讨论,我们将更好地了解AI技术在不同行业和日常生活中的作用,并预测未来AI工具的发展趋势。
常用AI工具 AI技术的快速发展和应用,给人们的生活和工作带来了诸多便利。以下是人们在日常生活或工作中经常使用的几种常见AI工具:
语音助手 (Voice Assistants):像Siri、Alexa和Google助手这样的语音助手已经成为人们生活中的重要伙伴。它们通过自然语言处理和语音识别技术,能够回答问题、播放音乐、发送消息、提供导航等。语音助手的便利之处在于它们能够通过语音指令完成许多任务,让人们更加高效和便捷地管理日常事务。
智能家居设备 (Smart Home Devices):智能家居设备,如智能音箱、智能灯泡、智能插座等,能够通过AI技术与人们进行交互,并根据个人需求进行自动化控制。例如,通过语音指令或手机应用,可以远程控制家中的灯光、温度、安防系统等。智能家居设备的便利之处在于它们能够增加居家舒适度,提高生活的便利性和安全性。
个性化推荐系统 (Personalized Recommendation System):个性化推荐系统广泛应用于电子商务、音乐和视频流媒体等领域。通过分析用户的历史行为和兴趣,AI工具可以为用户提供个性化的推荐内容。这使得用户能够更快地找到自己感兴趣的商品、音乐或电影,节省时间和精力。
自动翻译工具 (Automatic Translation Tool):随着全球化的发展,跨语言交流变得越来越重要。AI技术的应用使得自动翻译工具得以实现。这些工具使用机器翻译技术,能够快速准确地将一种语言翻译成另一种语言。自动翻译工具的便利之处在于它们能够为人们提供便捷的跨语言交流方式,促进国际合作和理解。
这些AI工具的实际应用和影响深远。它们不仅提高了个人生活的便利性和效率,还改变了各个行业的运作方式。AI技术的不断发展和应用,将进一步提升人们的生活质量,并推动社会的进步与发展。
创新AI应用 创新AI应用不断涌现,为人们提供了更多令人惊叹的功能和体验。以下是一些新颖的AI工具或应用,展示了AI技术不断创新和发展的方向:
智能医疗助手 (Intelligent Medical Assistant):AI技术在医疗领域的应用已经取得了令人瞩目的成果。智能医疗助手通过对巨大医学数据的分析,可以提供诊断建议、制定治疗方案,并监控患者的健康状况。这些助手能够在医生的决策过程中提供有价值的参考,帮助提高医疗质量和效率。
智能交通系统 (Intelligent Transportation System):智能交通系统利用AI技术对交通数据进行分析和预测,可以优化交通流量、提供实时的交通信息和路线建议,以及自动控制交通信号灯。这些系统可以减少交通拥堵、提高交通安全,并为人们的出行提供更加便捷的选择。
虚拟现实 (Virtual Reality) 和增强现实 (Augmented Reality):虚拟现实和增强现实技术在娱乐、教育和工业等领域有着广泛的应用。AI技术可以辅助虚拟现实和增强现实技术,使其更加智能化和交互性。例如,AI可以通过对用户的动作和表情的分析,提供更真实、沉浸式的虚拟体验。
自主驾驶汽车 (Autonomous Vehicles):自主驾驶汽车正在成为汽车行业的热门领域。AI技术在自主驾驶汽车中起到核心作用,通过感知、决策和控制系统来实现车辆的自动行驶。自主驾驶汽车的出现有望提高交通安全性、降低能耗,并改变人们对出行的方式和习惯。
这些新颖的AI工具或应用展示了AI技术的不断创新和发展。随着AI技术的进一步突破和应用,我们可以期待更多令人兴奋和有意义的AI工具和应用涌现,为人们的生活和工作带来更多的便利和改变。
个人体验分享 作为一个使用者,我个人体验过的最好用的AI工具是语音助手,如Siri和Alexa等。这些语音助手能够通过声控技术实现与用户的自然交流,帮助完成各种任务,如设置提醒、查找信息、播放音乐等。
语音助手给我带来了极大的便利。例如,我可以在开车或者做其他事情的同时,通过简单的口令就能够让语音助手为我完成一系列操作,而无需手动操作设备。此外,语音助手的智能学习功能可以逐渐了解我的习惯和喜好,从而提供更加个性化的服务。
使用语音助手的过程中,我对AI技术的进步感到非常震撼和启发。语音助手不仅依靠语音识别技术转化语音指令为文字,还需要通过自然语言处理和智能算法进行理解和回应。这种能够实现与人类自然交流的技术,展示了AI在语义理解和人机交互方面的巨大潜力。
对于未来AI技术的期望和展望,我希望AI能够继续发展,为人们提供更加智能、个性化和全面的服务。我期待看到AI在医疗、教育、环保等领域的深入应用,为社会带来更多的福祉。同时,我也希望AI能够更加注重隐私保护和伦理问题,确保技术的发展与人类价值的平衡。
总之,AI技术的不断进步和应用给我个人带来了巨大的便利和启发。我对AI技术的未来充满期待,相信它将继续为人类创造更多惊喜和改变。
后记 在本文的探讨中,我们发现人们在使用AI工具时最喜欢和认为最好用的工具有很多种类。无论是语音助手、智能家居设备、智能推荐系统还是语言翻译工具,这些AI工具都以其强大的功能和便捷的使用方式赢得了人们的青睐。
通过这些AI工具,人们可以实现更高效的工作、更智能的生活方式。例如,语音助手可以帮助人们处理日常事务、提供实时信息和解决问题,使得生活更加便捷。智能家居设备则可以通过自动化控制和智能化管理,提升家居的舒适度和能源利用效率。而智能推荐系统则可以根据个人的兴趣和偏好,为用户提供个性化的推荐内容和服务。
AI技术的实际应用也扩展到了许多行业和领域。医疗领域的AI工具可以辅助医生进行诊断、提供精准的治疗方案,改善医疗服务的质量。金融领域的AI工具可以帮助银行和保险公司进行风险评估和欺诈检测,提升金融安全性。制造业中的AI机器人可以提高生产线的效率和生产质量。这些实际应用充分展示了AI技术在各行各业中的潜力和重要性。
然而,随着AI技术的不断发展和应用,也带来了一些挑战和争议。隐私问题、劳动力失业以及道德和伦理问题都需要我们深入思考和解决。尽管如此,我们不能忽视AI技术所带来的巨大潜力和积极影响。
总的来说,AI工具在人们的日常生活和工作中发挥着越来越重要的作用。它们不仅提高了效率和便利性,还为我们带来了无限可能。随着AI技术的不断发展,我们可以期待更多创新和改进,为人类社会带来更大的进步和好处。
转载自:https://blog.csdn.net/u014727709/article/details/138742156
欢迎 👍点赞✍评论⭐收藏,欢迎指正
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化资料的朋友,可以戳这里获取
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
JupyteR是一个开源项目,通过十多种编程语言实现大数据分析、可视化和软件开发的实时协作。 它的界面包含代码输入窗口,并通过运行输入的代码以基于所选择的可视化技术提供视觉可读的图像。
但是,以上提到的功能仅仅是冰山一角。 Jupyter Notebook可以在团队中共享,以实现内部协作,并促进团队共同合作进行数据分析。 团队可以将Jupyter Notebook上传到GitHub或Gitlab,以便能共同合作影响结果。团队可以使用Kubernetes将Jupyter Notebook包含在Docker容器中,也可以在任何其他使用Jupyter的机器上运行Notebook。 在最初使用Python和R时,Jupyter Notebook正在积极地引入Java,Go,C#,Ruby等其他编程语言编码的内核。
除此以外,Jupyter还能够与Spark这样的多框架进行交互,这使得对从具有不同输入源的程序收集的大量密集的数据进行数据处理时,Jupyte能够提供一个全能的解决方案。
Tableau:AI,大数据和机器学习应用可视化的最佳解决方案 Tableau是大数据可视化的市场领导者之一,在为大数据操作,深度学习算法和多种类型的AI应用程序提供交互式数据可视化方面尤为高效。
Tableau可以与Amazon AWS,MySQL,Hadoop,Teradata和SAP协作,使之成为一个能够创建详细图形和展示直观数据的多功能工具。 这样高级管理人员和中间链管理人员能够基于包含大量信息且容易读懂的Tableau图形作出基础决策。
Google Chart:Google支持的免费而强大的整合功能 谷歌是当今领导力的代名词。正如谷歌浏览器是当前最流行的浏览器一样,谷歌图表也是大数据可视化的最佳解决方案之一,更不用说它是完全免费的,并得到了Google的大力技术支持。 为什么它能得到Google的支持? 因为通过Google Chart来分析的数据显然是要用于训练Google研发的AI,这样的合作对于各方来说都是双赢的。
Google Chart提供了大量的可视化类型,从简单的饼图、时间序列一直到多维交互矩阵都有。 图表可供调整的选项很多。如果需要对图表进行深度定制,可以参考详细的帮助部分。
该工具将生成的图表以HTML5 / SVG呈现,因此它们可与任何浏览器兼容。 Google Chart对VML的支持确保了其与旧版IE的兼容性,并且可以将图表移植到最新版本的Android和iOS上。 更重要的是,Google Chart结合了来自Google地图等多种Google服务的数据。 生成的交互式图表不仅可以实时输入数据,还可以使用交互式仪表板进行控制。
D3.js:以任何您需要的方式直观地显示大数据 D3.js代表Data Driven Document,一个用于实时交互式大数据可视化的JS库。 由于这不是一个工具, 所以用户在使用它来处理数据之前,需要对Javascript有一个很好的理解,并能以一种能被其他人理解的形式呈现。 除此以外,这个JS库将数据以SVG和HTML5格式呈现,所以像IE7和8这样的旧式浏览器不能利用D3.js功能。
从不同来源收集的数据如大规模数据将与实时的DOM绑定并以极快的速度生成交互式动画(2D和3D)。 D3架构允许用户通过各种附件和插件密集地重复使用代码。
最后的想法 以上提到的4种可视化工具只不过是大量在线或独立的数据可视化解决方案和工具中的一部分 。每家公司都能够找到最适合他们的工具,并能够使用这些工具帮助他们将输入的原始数据转化为一系列清晰易懂的图像和图表。 这些数据犹如埋藏在沙子里的黄金,需借助可视化做的决策帮助它们实现驱动价值的 - -数据可视化工具有助于确定趋势和模式,从而做出有证据支持的决策。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需要这份系统化资料的朋友,可以戳这里获取
https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需要这份系统化资料的朋友,可以戳这里获取
(lStart, lEnd) = FACIAL_LANDMARKS_68_IDXS[“left_eye”]
(rStart, rEnd) = FACIAL_LANDMARKS_68_IDXS[“right_eye”]
然后我们通过关键点只取两个ROI区域,就是左眼区域和右眼区域。 print(“[INFO] starting video stream thread…”)
vs = cv2.VideoCapture(args[“video”])
随后我们将视频读进来。 while True:
# 预处理
frame = vs.read()[1]
if frame is None:
break
(h, w) = frame.shape[:2]
width=1200
r = width / float(w)
dim = (width, int(h * r))
frame = cv2.resize(frame, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
将视频的展示框放大一点,这里很关键就是如果视频的框框设置的太小的话,可能无法检测到人脸。然后我们就把宽设置成了1200,然后对长度也同比例就行resize操作。最后转换成灰度图。 rects = detector(gray, 0)
这里面检测到人脸,将人脸框的四个坐标拿到手。注意就是必须要是对灰度图进行处理。 for rect in rects: # 获取坐标 shape = predictor(gray, rect) shape = shape_to_np(shape) 在这里进行人脸框遍历,然后检测68关键点。 def shape_to_np(shape, dtype=“int”):
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化资料的朋友,可以戳这里获取
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
}
**注意:** 该算法在具体实现时并不是先对一个子序列完成所有插入排序操作,再对另一个子序列进行,而是从第一个子序列的第二个元素开始顺序扫描整个待排序序列,当前待排序元素属于哪一个子序列,就在它相应的的子序列中进行排序。因而各个子序列地元素将会轮流出现,即算法将在每一个子序列中轮流进行插入排序。 **希尔排序总结:** > > 在希尔排序开始时增量(gap)较大,分组越多,每组的元素越少,因此各组内直接插入较快。后来增量逐渐缩小,分组数逐渐减少,每组内的元素个数越多,直接插入越慢,但是越接近有序。 > 时间复杂度在O(nlogn) ~ O(n^2) 之间,最好时间复杂度为O(n^1.3), 最坏时间复杂度为O(n^2)。 > 空间复杂度为O(1)。 > 希尔排序是一种不稳定的排序算法。 > > > ### 2. 选择类排序 选择类排序的基本思想是,在第 i 趟的序列中选择第 i 小的元素作为有序序列的第 i 个元素。该算法的关键就在于,如何从剩余的待排序序列中找出最小或最大的元素。 #### 2.1 简单选择排序 **动图演示:** 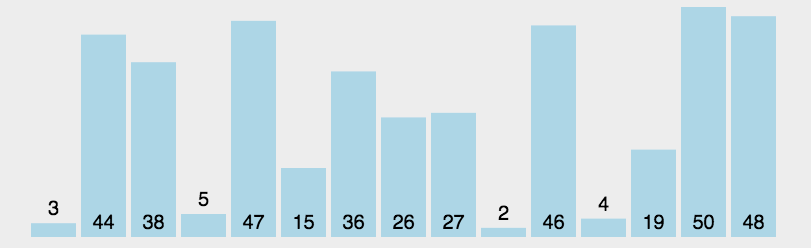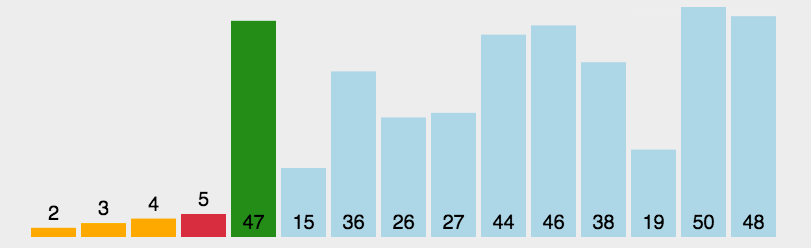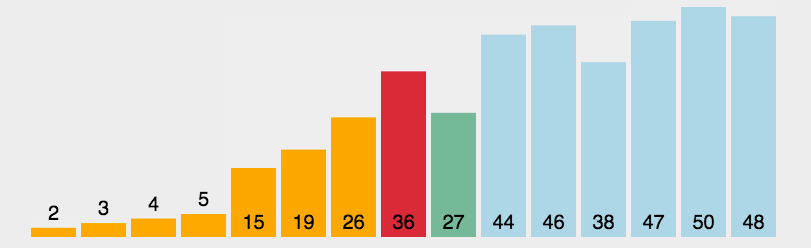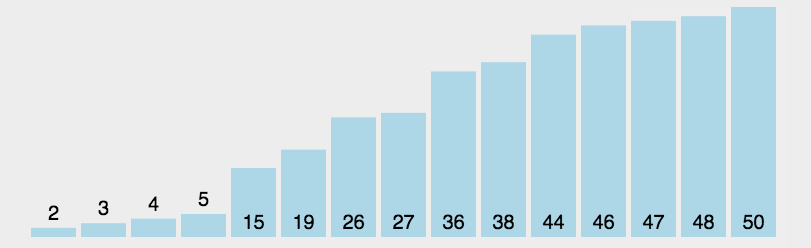 > > 基本思路:从第一个元素开始,从头向尾遍历,标记序列中最小的元素,待所有元素对比完之后与第一个元素交换;然后继续从第二个元素开始继续比较,直到完成最后只有两个元素的交换。 > > > **代码实现:** void SelectSort(int* array, int sz)
{
for (int i = 0; i < sz- 1; ++i)
{
// 找当前区间中最大元素的位置
int maxPos = 0;
for (int j = 1; j < sz- i; ++j)
1、Idea中使用Git 1.1、idea配置Git和Gitee 第一步:打开Idea,找到左上角file-->settings-->Version Control -> Git ,设置Path to Git executable的值为:本地git.exe所在位置如图:
点击测试会弹出本地git的版本号
第二步:还是在当前settings下找到Plugins搜索gitee,点击安装然后重启idea
第三步:配置gitee账号,如下图所示
登录到Gitee,点击 设置 -> 私人令牌,点击 +生成新令牌 即可生成私人令牌,最后将私人令牌复制到idea中即可(即使用私人令牌方式登录Gitee)。
1.2、Idea中分支操作 第一步:创建project,将project导入到gitee的远程仓库中!
导入成功后会有弹框,点击add即可!!!!(只是将文件上传到gitee中)
导入成功后会有弹框,点击add即可!!!!(只是将文件上传到gitee中)
导入成功后会有弹框,点击add即可!!!!(只是将文件上传到gitee中)
第二步:点击右下角Git:master,进行创建其他分支,如图操作
不同的分支也可以进行切换,点击你需要去到的分支就可以进行切换操作!
1.3、实践操作 1.3.1、将本地项目推送到远程 第一步:操作跟上面一致,只是不需要进行分支创建!
新增项目文件 提交到本地仓库 右键项目,选择Git -> Commit Directory,在弹窗中输入Commit Message,点击commit,此时项目文件从暂存区真正进入版本库(本地)中,项目文件变成白色。(这里要注意如果idea是白色风格,那么文件将会是黑色)
注:在弹窗中输入Commit Message,也可以点击commit and push,会同时提交到本地库和代码托管网站。
修改文件
修改已提交的文件后,此时文件将变成蓝色,蓝色代表已修改状态。
推送和拉取
右键项目点击 Git -> Repository -> Push,将本地项目推送到远程库。右键项目点击 Git -> Repository -> Pull,将远程库代码更新到本地。
1.3.2、从远程库克隆项目到本地 2、Git Flow 2.1、什么是Git Flow Git flow 是一种流行的 Git 分支管理工作流程,旨在帮助团队更好地组织和管理项目的开发过程。它基于一系列严格定义的分支,并规定了如何使用这些分支进行功能开发、版本发布等操作。
2.2、工作流程 Git flow 工作流程包括以下主要分支:
Master 分支: 主分支,用于存储稳定、发布的版本。通常只应包含已经发布或即将发布的代码。
🌹作者主页:青花锁 🌹简介:Java领域优质创作者🏆、Java微服务架构公号作者😄
🌹简历模板、学习资料、面试题库、技术互助
🌹文末获取联系方式 📝
往期热门专栏回顾 专栏描述Java项目实战介绍Java组件安装、使用;手写框架等Aws服务器实战Aws Linux服务器上操作nginx、git、JDK、VueJava微服务实战Java 微服务实战,Spring Cloud Netflix套件、Spring Cloud Alibaba套件、Seata、gateway、shadingjdbc等实战操作 Java基础篇Java基础闲聊,已出HashMap、String、StringBuffer等源码分析,JVM分析,持续更新中 Springboot篇从创建Springboot项目,到加载数据库、静态资源、输出RestFul接口、跨越问题解决到统一返回、全局异常处理、Swagger文档 Spring MVC篇从创建Spring MVC项目,到加载数据库、静态资源、输出RestFul接口、跨越问题解决到统一返回 华为云服务器实战华为云Linux服务器上操作nginx、git、JDK、Vue等,以及使用宝塔运维操作添加Html网页、部署Springboot项目/Vue项目等 Java爬虫通过Java+Selenium+GoogleWebDriver 模拟真人网页操作爬取花瓣网图片、bing搜索图片等 Vue实战讲解Vue3的安装、环境配置,基本语法、循环语句、生命周期、路由设置、组件、axios交互、Element-ui的使用等 Spring讲解Spring(Bean)概念、IOC、AOP、集成jdbcTemplate/redis/事务等 MySQL专栏回顾 专栏导航描述MySQL- -MySQL DDL通用语法MySQL- -MySQL DML通用语法MySQL- -MySQL 约束篇MySQL- -MySQL 多表查询MySQL- -MySQL 事务MySQL- -MySQL 存储引擎MySQL- -MySQL 性能分析MySQL- -MySQL 索引 前言 此为MySQL专栏文章之一,讲解MySQL 索引。
索引是帮助 MySQL 高效获取数据 的 数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查询算法,这种数据结构就是索引。
优点:
● 提高数据检索效率,降低数据库的IO成本
● 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点:
● 索引列也是要占用空间的
● 索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
1、索引结构 1.1、B-Tree [二叉树] 二叉树的缺点可以用红黑树来解决:
[红黑树] 红黑树也存在大数据量情况下,层级较深,检索速度慢的问题。
为了解决上述问题,可以使用 B-Tree 结构。
文章目录 前言准备工作代码实现引入依赖配置文件编写相关工具类实现验证码发送代码测试 前言 在日常生活中,通过发送邮箱验证码来实现用户注册、密码重置和账户验证等功能在许多现代应用程序中非常常见,这里采用hutool工具包封装的一些类实现发送邮箱验证码的功能。
准备工作 开启POP3/SMTP服务并获取授权码,具体操作很简单,这里就不演示了
网址:账号与安全 (qq.com)
代码实现 引入依赖 <!--hutool工具包--> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.11</version> </dependency> <!--html解析--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> <version>3.2.0</version> </dependency> <!--邮件发送--> <dependency> <groupId>com.sun.mail</groupId> <artifactId>javax.mail</artifactId> <version>1.6.2</version> </dependency> <!--redis--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> 配置文件 为了便于修改配置信息,因此要将邮件的相关配置写到配置文件application.yaml中
编写配置类 @Component @ConfigurationProperties(prefix = "captcha.email") @Data public class EmailProperties { /** * 邮箱地址(注意:如果使用foxmail邮箱,此处user为qq号) */ private String user; /** * 发件人昵称(必须正确,否则发送失败) */ private String from; /** * 邮件服务器的SMTP地址 */ private String host; /** * 邮件服务器的SMTP端口 */ private Integer port; /** * 密码(授权码) */ private String password; /** * 验证码过期时间 */ private Integer expireTime; } 编写相关配置信息到application.
基础部分学习:
1、 Llama 3 Web Demo 部署
streamlit run ***.py(网页演示py文件路径) ***(下载好的大模型参数路径) 注意点:在vscode中要对上面命令产生的External URL的最后四位端口号,在终端旁边的端口菜单中配置端口转发,否则无法在本地浏览器打开
实验结果:
2、使用 XTuner 完成小助手认知微调
本次微调使用的是QLoRA微调
微调数据集格式:
"conversation": [ { "system": "你是一个懂中文的小助手", "input": "你是(请用中文回答)", "output": "您好,我是洛希极限,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?" } ] 微调命令:
xtuner train ***(微调的**config.py配置文件路径) --work-dir ***(保存模型微调权重的目录:不存在会自动创建/自行命名) 微调完成后,要将Adapter PTH权重格式转化为 HF格式
xtuner convert pth_to_hf ***(微调的**config.py配置文件路径) ***(微调的工作路径/权重保存的路径) ***(转化后的存储路径) 将微调后得到的权重与预训练的权重进行合并:
export MKL_SERVICE_FORCE_INTEL=1 是一个环境变量设置命令,用于强制让使用Intel Math Kernel Library (MKL) 来进行数学计算,而不是使用其他的数学库。MKL是由英特尔提供的数学计算库,可以优化和加速数值计算、线性代数计算和傅里叶变换等操作。
xtuner convert merge ***(原始的Llama3权重路径)\ ***(刚刚准换好为HF(huggface格式)的adapter路径)\ ***(合并完成后的路径) 推理验证:
streamlit run ***.py(网页演示py文件路径) ***(合并完成后的路径的大模型参数路径) 实验结果:
3、使用 LMDeploy 成功部署 Llama 3 模型
很幸运拿了辽宁赛区的省一,进入6月1号的国赛啦...
这篇文章主要对第十五届省赛大学B组(C++)进行一次完整的复盘,这次省赛==2道填空题+6道编程题:
A.握手问题 把握手情景看成矩阵:
粉色部分是7个不能互相捂手的情况
由于每个人只能和其他人捂手, 所以黑色情况是不算的
1和2握手==2和1握手,就是只用算一半的对角矩阵
#include<iostream> using namespace std; int main(){ int a=0; for(int i=49;i;i--) a+=i; int b=0; for(int i=6;i;i--) b+=i; int ans=a-b; cout<<ans<<endl;//最后求得答案为1204 return 0; } B.小球反弹 这题考试的时候我是直接跳过的,到最后也没来得及看,看了估计也算不对,haha
整体思路是:
最终返回左上角时,小球走过的水平路程和垂直路程一定是343720和233333的偶数倍并且水平路程与垂直路程之比一定为15:17
对于后一个条件,很容易理解,因为两个方向上速度比是恒定的,接下来以极端情况简单说一下为什么只有到左上角小球走过的水平路程和垂直路程一定是343720和233333的偶数倍:
#include<iostream> #include<cmath> using namespace std; typedef long long ll; const int N=1e4; const ll X=343720; const ll Y=233333; int main(){ for(ll x=2;x<=N;x+=2){ for(ll y=2;y<=N;y+=2){ if (15*Y*y==17*X*x){ printf("%lf",sqrt((X*x)*(X*x)+(Y*y)*(Y*y))); //结果是1100325199.770395 return 0; } } } } C.
在实际应用中,我们经常需要从数据库中导出大量数据到CSV文件。如果数据量很大,一次性加载所有数据可能会导致内存溢出或者性能问题。为了解决这个问题,我们可以使用流式查询的方式逐行读取数据库,并将数据写入CSV文件,从而减少内存占用并提高性能。本文将介绍如何使用Java实现这一功能,并给出详细的代码示例。
准备工作 在开始之前,我们需要做一些准备工作:
确保你已经设置好了Java开发环境,并且具备基本的Java编程能力。确保你已经安装了相应的数据库,并且能够连接到数据库。确保你已经包含了相应的数据库驱动程序(如MySQL驱动)到你的Java项目中。 实现步骤 步骤一:连接数据库并执行流式查询 首先,我们需要连接到数据库,并执行流式查询来获取数据。在这个示例中,我们将使用JDBC连接MySQL数据库,并执行一个简单的查询语句。代码如下:
import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.io.FileWriter; import java.io.PrintWriter; public class DataExporter { public static void exportDataToCSV(String sqlStr, String csvFilePath) { try { // 连接数据库 Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/database", "username", "password"); // 执行流式查询 PreparedStatement stmt = conn.prepareStatement(sqlStr, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY); stmt.setFetchSize(Integer.MIN_VALUE); ResultSet rs = stmt.executeQuery(); // 写入CSV文件 PrintWriter writer = new PrintWriter(new FileWriter(csvFilePath)); while (rs.next()) { // 将查询结果写入CSV文件 // 例如:writer.println(rs.getString("column1") + "
文章目录 1.基本介绍2.Linux下安装配置RabbitMQ1.安装erlang环境1.将文件上传到/opt目录下2.进入/opt目录下,然后安装 2.安装RabbitMQ1.进入/opt目录,安装所需依赖2.安装MQ 3.基本配置1.启动MQ2.查看MQ状态3.安装web管理插件4.安装web管理插件超时的解决方案1.修改etc/hosts文件,修改主机名2.重启MQ如果还报错就修改ip与本机ip相同 5.设置开机自启6.关闭MQ7.组合指令1.启动MQ并查看状态2.关闭MQ并查看状态3.重启MQ并查看状态 4.RabbitMQ管控台配置1.开放15672端口1.宝塔开启2.腾讯云开启,仅限本机登录 2.访问 http://ip:15672 进行登录1.使用guest用户登录,出现权限问题2.进入/etc/rabbitmq 编辑 rabbitmq.config3.将下面这句话粘贴进去4.重启MQ,使配置生效5.再次登录,成功! 3.控制台参数解析1.端口2.交换机,默认七个 4.用户管理1.进入Admin2.添加用户test,默认不能访问虚拟主机3.给test用户分配可以访问的虚拟主机4.为了安全,修改guest用户的密码 5.增加虚拟主机1.添加/test的虚拟主机2.配置test用户可以访问虚拟主机/test3.删除test用户 5.SpringBoot集成MQ1.需求分析2.环境配置1.引入依赖2.MQ的端口配置1.编辑MQ的配置文件2.修改端口5672为6783(防止被攻击)3.重启MQ使其生效4.测试是否成功5.宝塔开启6783端口6.腾讯云开启 3.配置application.yml4.RabbitMQ配置类创建队列 RabbitMQConfig.java 3.基本使用1.编写消息发送者 MQSender.java2.编写消息接受者 MQReceiver.java3.控制层调用发送消息的方法4.启动测试1.访问 http://localhost:9092/seckill/mq 成功发送和接受消息2.http://ip:15672 在控制台可以进行监控 1.基本介绍 2.Linux下安装配置RabbitMQ 1.安装erlang环境 1.将文件上传到/opt目录下 2.进入/opt目录下,然后安装 cd /opt && rpm -ivh erlang-21.3-1.el7.x86_64.rpm 2.安装RabbitMQ 1.进入/opt目录,安装所需依赖 cd /opt && yum install socat -y 2.安装MQ rpm -ivh rabbitmq-server-3.8.8-1.el7.noarch.rpm 3.基本配置 1.启动MQ /sbin/service rabbitmq-server start 2.查看MQ状态 /sbin/service rabbitmq-server status 3.安装web管理插件 rabbitmq-plugins enable rabbitmq_management 4.安装web管理插件超时的解决方案 1.修改etc/hosts文件,修改主机名 2.重启MQ如果还报错就修改ip与本机ip相同 5.设置开机自启 chkconfig rabbitmq-server on 6.关闭MQ /sbin/service rabbitmq-server stop 7.