一、准备需要用到的工具(以我的环境做参考window10),如下: 1)java环境,java jdk 1.8.0_411
2)安装Node.js (v19.9.0)
3)安装appium服务端:appium-desktop-Setup.exe ([Appium] Welcome to Appium v1.7.2)
4)安装Android Studio (SDK)
5)安装appium client (python)
6)测试 (启动APP)
二、环境配置 步骤一:安装java jdk环境 1)这个下载后傻瓜式安装即可,安装完成后必须配置环境变量,具体配置可百度或CSDN
步骤二:安装Node.js 1)node.js是appium的解释器,因为appium是使用nodejs实现的,简单的说Node.js就是运行在服务端的JavaScript;官网下载地址:Node.js — Run JavaScript Everywhere,下载Recommended For Most Users
2)安装Node.js
点击Next
设置安装路径后点击Next
点击Next
[勾选会自动安装必要的工具]点击Next
点击Install
等待安装(很快完成)
点击Finish
安装完成后会CMD终端提示(此脚本将安装必要的 Python 和 Visual Studio 构建工具 编译 Node.js 原生模块。请注意 Chocolatey 和所需的 Windows 还将安装更新。 这将需要大约 3 GiB 的可用磁盘空间,加上任何必要的空间 安装 Windows 更新。可以关闭此窗口立即停止。安装这些的详细说明 手动工具可在 https://github.com/nodejs/node-gyp#on-windows 上找到
)此处建议关闭CMD终端窗口,后续需要再手动去配置
安装完成后,将node.js的安装路径加入到path环境变量中(也就是node.exe所在的目录,例如:E:\Nodejs),(一般情况下安装完后会自动加入path中的,需要再次确认环境变量中有没有添加)
添加环境变量:此电脑-属性-高级系统设置-环境变量
验证环境变量配置成功:打开cmd窗口,验证是否安装成功,输入:npm
出现这个说明node.js安装成功
文章目录 一、文章背景二、实现步骤2.1、需要的环境2.2、创建模板2.3、书写java类2.4、测试 三、freemarker技术点3.1、简介3.2、常用语法3.3、某些标签的意思3.4、常见问题 四、其他导出word实现方式 一、文章背景 公司的某个需求,需要根据接口的信息生成一份word接口文档信息并支持导出功能。以前没做过这种需求,于是搜罗各种资料,最终发现java利用freemarker模版可以实现这个功能。
二、实现步骤 2.1、需要的环境 <!--springboot父依赖--> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.6.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <!--springboot启动器依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!--freemarker依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-freemarker</artifactId> </dependency> 2.2、创建模板 1)展示word文档如下所示:
2)将word文档动态的参数替换成占位符,如下所示:
3)word另存为xml格式保存
4)将xml文件更改为ftl文件
2.3、书写java类 1)将上一步生成的ftl文件重命名cdsnUser.ftl放到resource目录的templates文件夹下面,并格式化文件
ps:
1.1)因用户列表是list集合遍历的形式动态展示,所以需要遍历列表标签并展示数据。遍历的语法如下:<#list 集合 as 对象名> </#list>
1.2)注意此处对象别名要和生成word占位符的属性对应上,不然取不到值
1.3)标签是行的意思,遍历的范围要对,不然word打不开或者后台报错
2)新建User类
import lombok.Data; @Data public class User { private String name; private String sex; private String iphone; private String idcard; private String idNum; } 3)wordUtil工具类
2024届SLAMer秋招算法岗面试题总结 1 实习面试篇禾多科技小米Nreal极智嘉 2 秋招面试篇商汤南测(线下)影石零束中移上研院(线下) 先说一下本人的情况,研究方向视觉slam+多传感器融合,bg双985,一篇SCI二区,项目做的比较水。
起初目标瞄准算法岗,结果从实习开始就没找到,秋招更是一片惨淡,进面试的概率是1/10,只拿到一个算法岗offer,很遗憾,最后决定彻底放弃算法了。
如果有正在面临春秋招的slamer看到这篇博客,希望能给到你一点帮助。
算法岗要准备的内容包括:
slam十四讲基础理论:PNP、本质矩阵、基础矩阵、单应性矩阵、Ransac、对极约束、李群李代数等项目细节:算法原理、流程、创新点、设备平台、标定、场景问题等C++编程基础:三大特性、指针、引用、数据类型,个别情况会问到开发中的进程线程、垃圾处理等力扣刷题:个人观感,要过大厂笔试,只刷简单和中等是不够的常用开源算法框架:做视觉要熟悉VINS、ORB-SLAM、GVINS,初始化、重投影、预积分这些要非常熟练,优化库像ceres里的编程过程也要熟悉(可选)视觉方向非常非常建议你去搞点深度学习,传统方法去面试感觉真不够用了(可选)嵌入式平台开发(可选)opencv图像处理(可选)数据库 1 实习面试篇 禾多科技 围绕项目提问,每一个项目都会问到,非常关注深度学习应用
线特征是用什么提取的线特征和消失点是怎么构建残差为什么要做分割、分割的精度有没有做过用深度学习做前端数据集是怎么做的,网络输入输出怎么设计的检测结果衡量指标,对于误检测和漏检测怎么处理对于车载前向单目,怎么实现逆向的重定位匹配?加后视、环视NetVLAD提取到描述子的过程是怎么实现的有没有做过嵌入式平台的部署 C++部分
const用法(主要是函数传值)指针和引用的区别(是否需要初始化)vector怎么分配指定的内存空间,怎么释放resize和reverse的区别 小米 一面
先问项目,再写代码
线特征残差是怎么构造的,消失点约束是怎么构造的,几何意义点线特征在做优化的时候,信息矩阵是怎么给的IMU预积分姿态是怎么推的陀螺零偏随机游走、加速度零偏随机游走在哪里有用到 代码手撕
Leetcode第一题 两数之和(哈希表)
二面
消失点怎么构建对于图像匹配错误的情况怎么解决MSCKF简单讲一下这个系统架构,它的滤波状态量有什么,对于地图点是怎么处理的优化和滤波各有什么特点,你觉得哪种应用更好 基础知识部分
为什么要用李群和李代数边缘化是怎么做的 C++部分
常量指针和指针常量函数传参 什么时候用引用,什么时候用指针虚函数的作用 Nreal 非常注重公式原理的考查
线特征自由度、表示方法、对极约束是怎么建立的消失点的约束是怎么建立的LBD描述子是怎么实现的标定(用的什么相机、标定板大小尺寸、标定精度重投影误差、怎么评价内外参标定结果的好坏)两个图像帧各有一百个跟踪点 怎么区分内点和外点VIO和GNSS做滤波,有哪些状态量,对于高楼有遮挡条件下怎么处理对极约束公式BA问题求雅可比维度(3个相机6个量,10个地图点3个量)60*48 写代码(打开vs共享屏幕)
一个nums数组求第k大的元素(力扣题,快排)
极智嘉 这边做激光应用,并且表示不用视觉方案,所以没有对视觉SLAM做深挖
对于车体前进方向上怎么做约束最小二乘和卡尔曼滤波的区别,有什么相同点,优缺点卡尔曼滤波是关联相邻两个时刻,怎么能够关联多个时刻 编程题
给一个二维的vector,存储平面特征点坐标xy
拟合平面直线(思路就是构建Ax=b方程,编程实现)
2 秋招面试篇 商汤 先问项目,再问slam14讲,再问C++
开阔场景和隧道场景怎么处理出隧道后轨迹存在跳变怎么解决,怎么平滑处理卡尔曼滤波基本原理VINS初始化基本流程E、F、H矩阵都需要几个点Ransac原理SVD分解有奇异性问题吗BCH近似 C++
reverse和resizevector和list自定义类型排序,对自定义类型有什么要求赋值构造和拷贝构造static关键字修饰类成员变量和函数对于常量的初始化,可以放在构造函数里面吗,在哪初始化week_ptr有什么用处,会增加引用计数吗左值引用和右值引用虚函数表指针存在什么地方,是父类子类都有还是共用非静态成员函数可以调用静态成员变量吗 南测(线下) 介绍项目,问slam基础,场景方案设计题
VINS、GVINS框架流程有没有学过摄影测量,前方交汇场景题:无人机战场下观测,确定一个目标的位置,怎么设计一套方案视觉方案成果验收,提供哪些指标怎么看待传统测绘行业和车企互联网 影石 围绕项目问,没有C++和编程考查
问项目中用的设备类型,惯导零偏参数水平GNSS/INS滤波组合过程怎么解决抖动问题 零束 围绕项目问,没有C++和编程考查,流程很快十几二十分钟
卡尔曼滤波流程,EKF为什么要做线性化问项目设备 中移上研院(线下) 视觉定位本质是观测什么kalibr标定原理车载Z轴激励不够怎么办如果GNSS各种方差协方差指标都很好,但观测质量有问题,怎么剔除
一、配置路由器登录方式
1、配置路由器管理IP
<Huawei> system-view [Huawei] interface gigabitethernet 0/0/0 [Huawei-GigabitEthernet0/0/0] ip address 192.168.1.1 24 [Huawei-GigabitEthernet0/0/0] quit 2、启用http
[Huawei] http secure-server enable 3、配置Web用户和用户级别
以用户名admin ,密码123为例
[Huawei] aaa [Huawei-aaa] local-user admin password cipher 123 [Huawei-aaa] local-user admin privilege level 15 [Huawei-aaa] local-user admin service-type http [Huawei-aaa] return <Huawei> save 二、配置Telnet登录
华为Telnet登录验证方式:
AAA方式:使用用户名+密码方式登录。
Password方式:使用用户名+密码方式登录。
(一)AAA方式:
<Huawei> system-view [Huawei] user-interface vty 0 [Huawei-ui-vty0] protocol inbound telnet [Huawei-ui-vty0] authentication-mode aaa [Huawei-ui-vty0] quit [Huawei] aaa [Huawei-aaa] local-user admin123 password irreversible-cipher YsHsjx_202206 [Huawei-aaa] local-user admin123 service-type telnet [Huawei-aaa] local-user admin123 privilege level 15 [Huawei-aaa] return <Huawei> save (二)Password方式
文章目录 前言
一、whisper是什么?
二、使用步骤
1.安装
2.python调用
3.识别效果评估
4.一点封装
5.参考链接
总结
前言 随着AI大模型的不断发展,语音识别等周边内容也再次引发关注,通过语音转文字再与大模型交互,从而实现语音与大模型交互。
今天我们介绍下语音识别领域的顶级选手whisper。
一、whisper是什么? whisper是openai开源的语音识别模型,也是使用了Transformer架构。
openai宣称whisper的语音识别能力已经到了人类的水平。
接下来我们参考Github结合其他技术博客内容,实操下whisper的使用。
二、使用步骤 1.安装 1)pip安装whisper
pip install -U openai-whisper 2)安装ffmpeg
下载地址:ffmpeg下载地址https://github.com/BtbN/FFmpeg-Builds/releases
选择对应操作系统的安装包即可
Linux系统也可以直接命令方式安装。
对于Windows系统,下载到本地后解压缩即可,但是需要设置环境变量,路径bin(就是在这个路径下有ffmpeg.exe)
特意说明:whisper内部其实调用了ffmpeg,使用的就是cmd形式,应该是将音频文件转为流式以及按时间段分成小段音频(最终识别结果就是按时间段分开的)
2.python调用 import whisper model = whisper.load_model("base") result = model.transcribe("audio.mp3") print(result["text"]) 第一次运行的时候,首先需要下载模型文件,base属于比较小尺寸的模型,还有small、large等。
另外如果可能报错,可以尝试重启下开发工具再试,可能就好了(我就遇到这种问题,可能没有重启开发工具,找不到ffmpeg)
3.识别效果评估 我使用了一个11分钟的会议录音文件测试。CPU环境。
使用base模型,用时约2分钟,质量还行
使用small模型,用时约4分钟,质量比base模型的好一些,但是有些反而不如base模型的。
整体上,还行吧。
4.一点封装 由于不同大小的模型识别速度上还是差不少,因此还要结合实际情况选择使用哪个模型,基于这个基础对调用做了一点封装
import whisper from datetime import datetime # 模型根路径 model_root="E:\Models\whisper" class whisper_utils: # model_name="base" # model_name="small" def __init__(self,model_name="base"): self.model = whisper.load_model(name=model_name,download_root=model_root) def audio_to_txt(self,audio_file: str): now = datetime.
一、使用场景
发布者设置需要发布的公告内容、公告接收用户和发布时间,到达发布时间时及时通知提醒已登录系统用户,使用websocke来实现前端与服务器保持长连接,以便实时过去公告信息。
WebSocket是一种在单个TCP连接上进行全双工通信的协议。这种协议使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。WebSocket基于TCP传输协议,并且复用HTTP的握手通道,即基于HTTP的"keep-alive"机制,允许在一次TCP连接中传送多个HTTP请求和响应。WebSocket的通信过程大致如下:在建立WebSocket连接时,客户端会向服务器发送一个HTTP请求报文,其中包含升级协议的请求头。服务器在接收到该请求后会返回一个HTTP响应报文,其中包含升级协议的响应头。在收到服务器的响应后,客户端和服务器之间的连接就会升级为WebSocket连接,此时客户端和服务器之间的通信就不再需要使用HTTP协议的请求和响应报文,而是直接进行双向数据传输。WebSocket协议的特点包括: 较少的控制开销:在连接创建后,服务器和客户端之间交换数据时,用于协议控制的数据包头部相对较小。更强的实时性:由于协议是全双工的,所以服务器可以随时主动给客户端下发数据。保持连接状态:与HTTP不同的是,WebSocket需要先创建连接,这就使得其成为一种有状态的协议,之后通信时可以省略部分状态信息。更好的二进制支持:WebSocket定义了二进制帧,相对HTTP,可以更轻松地处理二进制内容。可以支持扩展:WebSocket定义了扩展,用户可以扩展协议、实现部分自定义的子协议。与HTTP长连接相比,WebSocket连接在数据传输效率和实时性方面具有明显优势。HTTP长连接中,每次数据交换除了真正的数据部分外,服务器和客户端还要大量交换HTTP
header,消息交换效率低。而WebSocket连接在建立后,可以直接进行双向数据传输,无需反复建立连接和发送HTTP请求,从而大大提高了数据传输效率和实时性。总之,WebSocket是一种高效、实时的全双工通信协议,适用于需要实时通信和数据传输的场景。 二、实现过程
封装自定义websocket服务 import config from "./config" /** 自定义websocket服务 */ export default class SocketService { /** * 单例 */ static instance = null static get Instance() { if (!this.instance) { this.instance = new SocketService() } return this.instance } /** 和服务端连接的socket对象 */ ws = null /** 服务器连接地址 */ wsUrl = null /** 连接用户Id */ userId = null /** 存储回调函数 */ callBackMapping = {} /** 标识是否连接成功 */ connected = false /** 重新连接间隔(ms) */ connectRetryTime = 3000 /** 重新连接次数 */ connectRetryCount = 0 /** 定义连接服务器的方法 */ connect(_userId) { // 连接服务器 if (!
在Midjourney中,使用艺术家的关键词可以引导AI生成具有特定艺术家风格特征的图像。以下是一些常见的艺术家关键词及其可能的效果:
1. **达芬奇风格**(Leonardo da Vinci Style):可能会生成具有文艺复兴时期特征的作品,如精细的线条、深邃的色彩和逼真的光影效果。
2. **梵高风格**(Van Gogh Style):可能产生具有强烈色彩对比和涡旋状笔触的图像,模仿了梵高的后印象派风格。
3. **毕加索风格**(Picasso Style):可能会创造出立体主义风格的图像,特点是几何形状的分解和重组。
4. **莫奈风格**(Monet Style):可能生成印象派风格的图像,以模糊的轮廓和明亮的色彩为特点。
5. **浮世绘风格**(Ukiyo-e Style):可能会产生具有日本传统美学特征的作品,如平面构图和细腻的线条。
6. **中国国画风格**(Traditional Chinese Painting Style):可能生成具有中国水墨画特点的图像,如留白、墨色层次和线条流动性。
7. **哥特式艺术风格**(Gothic Art Style):可能创造出具有神秘氛围和复杂装饰性的黑暗或中世纪风格的图像。
8. **科幻艺术风格**(Science Fiction Art Style):可能产生描绘未来想象世界的创新和充满科技感的图像。
9. **插画风格**(Illustration Style):可能生成表现力丰富且多样化的插图,这些插图可能包括卡通、现实主义或超现实主义等多种风格。
通过结合这些关键词,用户可以指导AI创造出具有特定艺术家风格的图像,从而在Midjourney的艺术创作旅程中实现个性化的表达。
词汇效果描述使用说明/范例等特定艺术家Alfons Maria Mucha阿尔丰斯·慕夏Alexandre Cabanel was亚历山大·卡巴内尔法国学院派画家pablo picasso毕卡索抽象画Seurat秀拉印象派点画法Raffaello Sanzio da Urbino拉斐尔文艺复兴三杰Michelangelo米开朗基罗文艺复兴三杰Leonardo da Vinci达文西文艺复兴三杰Sandro Botticelli坡堤切利文艺复兴画家 维纳斯的诞生Jean-Honoré Fragonard洛可可时代最后一位代表画家Gustav Klimt易产生大块面的金黄色、碎状肌里Gustav Klimt保罗 塞尚后印象派Alfons Maria Mucha阿尔丰斯·慕夏Vincent van Gogh文森梵谷后印象派Diego rivera迪亚哥·里维拉墨西哥画家Edvard Munch爱德华·孟克吶喊的画家Paul Gauguin保罗高更后印象派Salvador Dali达利Monet莫内Wassily Kandinsky康丁斯基色块感浓厚O'Keeffe欧姬芙花卉抽象女性Kazimir Malevich蒙德里安抽象主义Piet Mondrian抽象主义Andy Warhol安迪沃荷普普艺术Katsushika Hokusai葛饰北斎浮世绘大师TAKEHISA YUMEJI竹久梦二大正时代的浪漫主义画家Gustave Doré古斯塔夫·多雷19世纪法国艺术家、版画家、漫画家、插画家和木雕雕刻家Tan Yin唐寅就是唐伯虎,国画风格Katsushika Hokusai葛饰北斋Ilya Efimovich Repin列宾俄国巡回画派The WanderersDaniel Merriam超现实主义画家Sandra Dieckmann英文名译名说明Junji Ito伊藤润二Zhang Daqian张大千它理解的有点怪伊东深水上村松园尾田荣一郎尾田荣一郎Yoshitaka Amano天野喜孝Katsuhiro Otomo大友克洋Yoshitomo Nara奈良美智Takashi Murakami村上隆后现代艺术、奇想、缤纷ghibli studio吉卜力工作室Makoto Niitsu新海诚Hayao Miyazaki宫崎骏Fuji Choko藤ちょこJames Jean以商业作品以及画廊艺术品闻名妈的多重宇宙-海报设计师greg rutkowski11Craig Mullins史诗感大场景Sylvain SarrailhPeter Mohrbacher各种天使画像(以诺书里的天使)NekroRembrandt林布兰黑底剧场光油画Mike mignola水Dan Mumford经典电影海报插画Ross Tran2.
Java 变量类型 在 Java 语言中,所有的变量在使用前必须声明。
声明变量的基本格式如下:
type identifier [ = value][, identifier [= value] …] ;
格式说明:
type – 数据类型。
identifier – 是变量名,可以使用逗号 , 隔开来声明多个同类型变量。
以下列出了一些变量的声明实例。注意有些包含了初始化过程。
int a, b, c; // 声明三个int型整数:a、 b、c
int d = 3, e = 4, f = 5; // 声明三个整数并赋予初值
byte z = 22; // 声明并初始化 z
String s = “runoob”; // 声明并初始化字符串 s
double pi = 3.14159; // 声明了双精度浮点型变量 pi
char x = ‘x’; // 声明变量 x 的值是字符 ‘x’。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需要这份系统化的资料的朋友,可以戳这里获取
end_task4 = BashOperator( task_id='end\_task', bash_command='echo "end task"', dag=dag, ) say_hello_task >> [print_date_format_task2,print_date_format_task3] >> end_task4 ``` + **提交** ``` python second_bash_operator.py ``` + **查看** 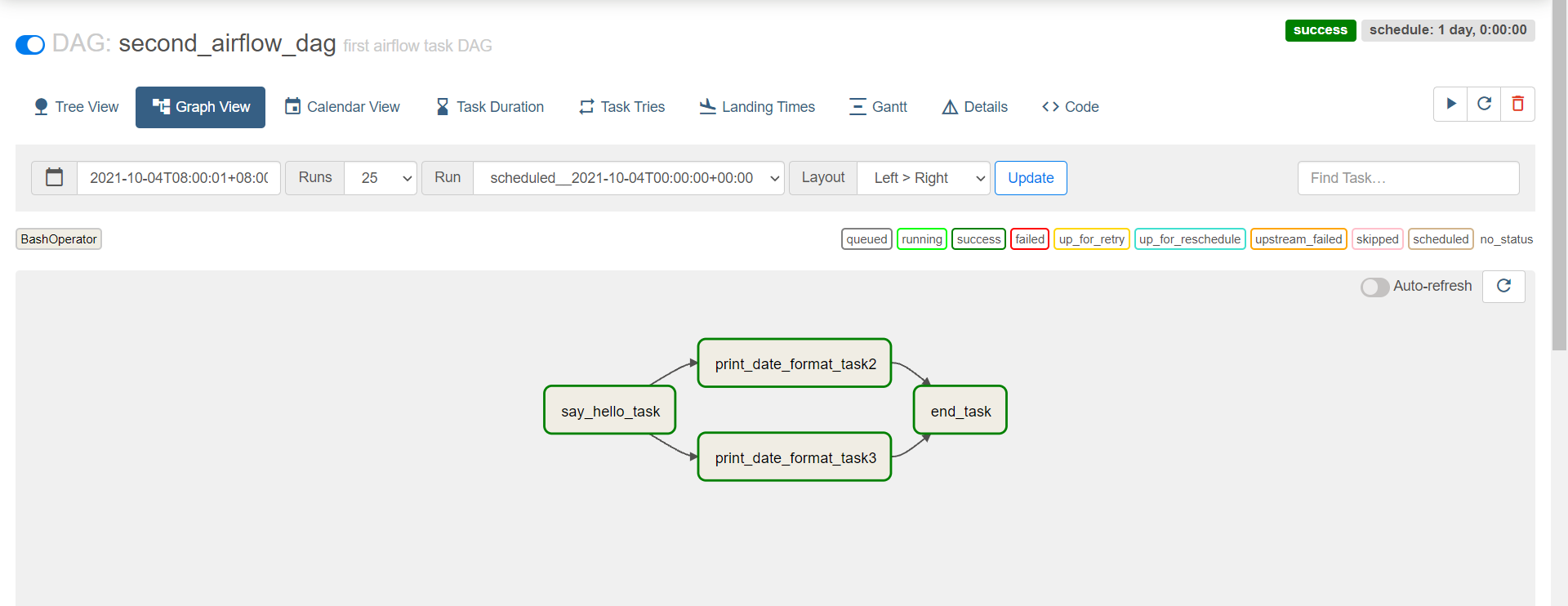 小结
实现AirFlow的依赖调度测试 知识点09:Python调度测试 目标:实现Python代码的调度测试
实施
需求:调度Python代码Task的运行
代码
创建 cd /root/airflow/dags vim python_etl_airflow.py 开发 # import package from airflow import DAG from airflow.operators.python import PythonOperator from airflow.utils.dates import days_ago import json # define args default_args = { 'owner': 'airflow', } # define the dag with DAG( 'python\_etl\_dag', default_args=default_args, description='DATA ETL DAG', schedule_interval=None, start_date=days_ago(2), tags=['itcast'], ) as dag: # function1 def extract(\*\*kwargs): ti = kwargs['ti'] data_string = '{"
温馨提示 关于本文:
本文你可以学习到完整的不使用webui借助lora和dreambooth微调Stable Diffusion的全过程。
手把手教你微调Stable Diffusion生成优弧,但是半失败版😂
关于训练:
单卡32GV100进行的微调,因为一些训练策略显存只需要16G就够了。
训练用时一个半小时多一点点。根据自己显卡量力而行。
搞环境 先搞个虚拟环境:
conda create -n youhu
conda activate youhu scipy
进入虚拟环境了。开搞。
因为我们是使用DreamBooth对Stable Diffusion进行微调,所以先把Diffusion Model的库搞下来。
git clone https://github.com/huggingface/diffusers.git
下载成功之后你现在会看到多出来一个diffuser文件。
然后进入到这个文件夹了里。开始安排环境
pip install -e .
进入examples/dreambooth目录,继续安排环境的依赖包:
pip install -r requirements_sdxl.txt
pip install bitsandbytes xformers
配置一下accelerate的环境
accelerate config default
数据集 接下来就是准备几个你小子的图。放到examples/dreambooth目录下。
准备脚本 打开vim写个脚本,代码下拉可以直接复制。
这个脚本是使用你刚才的图片通过Dreambooth微调Stable Diffusion模型。
export MODEL_NAME="./stable-diffusion-xl-base-1.0" export INSTANCE_DIR="yh" export OUTPUT_DIR="lora-trained-xl" # export VAE_PATH="madebyollin/sdxl-vae-fp16-fix" python train_dreambooth_lora_sdxl.py \ --pretrained_model_name_or_path=$MODEL_NAME \ --instance_data_dir=$INSTANCE_DIR \ --output_dir=$OUTPUT_DIR \ --instance_prompt="
别以为TJ君说的是天方夜谭,就在前不久的 GitHub Universe 2021开发者大会上,GitHub官方正式宣布了一款名为 Copilot工具的更新。
说起Copilot这个名字,相信一直关注GitHub的小伙伴马上脑海中会浮现出今年早些时候看到的新闻。
就在今年夏天,GitHub 官方和OpenAI联合发布了一款AI自动编程工具,其名字正是 GitHub Copilot 。就像前文TJ君想的那样,通过Copilot,程序员只需输入注释,即可自动生成代码!
当时一时间在程序猿圈子里还引起了不少的轰动,但更多的是对这个工具的疑问,还因此引发了一个快速平方根倒数算法事件。
快速平方根倒数算法,是当年红极一时的雷神之锤3(Quake 3,也是TJ君当年的最爱之一)的开发者约翰·卡马克用的一段代码。
卡马克大神
这段使用多项式逼近计算平方根的代码,至今都没什么人能明白卡马克的脑子是怎么想出来的,以至于这段代码阿注释直接是what the f***?很贴切了
而有开发者在Copilot发布后不久就发现,只要输入 快速平方根倒数算法(Fast Inverse Square Root,当然是英文)作为注释,Copilot 就会逐行逐字地重现了这段神奇的算法,一字不差,甚至连那个夸张地注释都没变。
这下子仿佛在程序猿小伙伴中间投了颗原子弹,大家都在问难道Copilot只是把别人的代码拿来复制一下就是所谓地自动生成了?
那这之后各种版权问题咋搞,万一用了Copilot生成一段代码却被人起诉了怎么办?甚至有科技公司直接宣布禁止旗下员工使用Copilot开发公司产品,就是为了减少不必要的麻烦。
一时间各种针对Copilot地非议愈演愈烈,甚至传出了自动生成内容是某个公司大佬身份证这样的消息,当然后来被澄清是一个笑话。
但是GitHub并没有退缩,认为Copilot并没有简单的抄袭其他人的内容,而是经过大量训练的AI自动生成所需代码,和抄袭完全是两回事。反正这件事情后来也么了下文,当时Copilot也只支持 Visual Studio Code。
不过前几天的这次更新之后,Copilot将全面支持Neovim 和 JetBrains IDE,包含开发者常用的 IntelliJ IDEA、PyCharm 等。同时增加了对 Java 中多行补全的支持,并计划在未来几个月内支持Python、Java、Type、Ruby 和 Go之外更多的语言,似乎真的是要大干一场。
如果想用Copilot的话,需要将 IntelliJ IDEA 和 PyCharm 升级到 2021.2 或以上版本、Neovim 的版本则需要升级成 0.6 或以上版本,并且需要安装 Node.js v12 或以上版本。
安装重启之后就可以在工具栏看到安装好的Copilot
然后登陆GitHub账号,同意相关条款
那说了那么久,这款号称可以自动编码的插件具体使用效果如何呢?就让TJ君带你领略一下或许是未来的编码趋势与潮流:
例如在项目里新建了test类,Copilot马上就会给一个建议生成的主体
此时只需要轻按一下tab键,就可以接受建议自动生成,无需手打这段代码。
同样的如果输入了一个函数标题,也会自动出现推荐的函数主体内容,一样是用tab键接受。
当然,Copilot不止会给出单一的自动编码推荐,用户可以使用Alt+]或者Alt+[来逐个切换不同的推荐,就像逐个挑选一件件商品一般,选中之后轻按一下tab键使用即可。
而通过Alt+Enter可以直接打开各种推荐的列表,便于查找。
至于TJ君之前梦想的根据注释自动生成代码,有一个前提就是必须输入的注释能让机器看懂,也就是说,需要英文注释。当输入中文注释,Copilot不一定看得懂含义,毕竟中文可是博大精深滴。。。
最后 自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
小时候比较喜欢画画,如今AI盛行,各种绘画工具层出不穷,网上也看了很多,stable diffusion(sd)和midjunery(mj)算是主流,国内的文心、天工、甚至抖音什么的,我也尝试过,但是总的来说,跟sd和mj相比真的不好用。后来我找了网上一些运营号问,大多采用的是mj,不过我个人还是想试试,亲自对比一下,鉴于mj的付费,我先试了sd,(附安装包)
下面是我安装使用过程中的一些经历。
我的是Mac,所以就按照这个系统来了
一、安装homebrew $ /bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.sh)" // 等待即可,检查是否安装成功 brew -V // 打印出 homebrew 4.0.11 表示安装成功 二、安装python brew install cmake protobuf rust python@3.10 git wget 也可以去官网下载安装包3.10.9 或者3.10.10,手动安装
三、下载SD包(附安装包) 1、下载资料包,解压安装。
2、从git仓库直接下载
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui 四、下载模型 可以使用上面资料包里的模型,
这里需要注意的是,下载后放置目录stable-diffusion-webui/models/Stable-diffusion/下。模型有ckpt文件,也有safetensors文件,统统放进去就行。
五、运行 在终端中进入你安装的“stable-diffusion-webui”目录,运行 ./webui.sh
第一次运行会安装一些依赖,这个过程会遇到诸多问题,下面我列举几个。
六、运行问题解决 1、python版本问题 🔗
sd运行python是3,但是默认是2,一般来说是不进行覆盖的,覆盖它可能会导致系统脚本和其他依赖默认 Python 的软件出现问题。一般我们采用软连的方式,如:sudo ln -s /usr/local/bin/python3 /usr/bin/python,但是你会发现报错了ln: /usr/bin/python: Operation not permitted,也查过其他各种删除方式都不得行。
首先安装高版本的python后,按照下面的步骤来:
(1、查看版本
which python // /usr/bin/python which python3 // /usr/local/bin/python3 (2、编辑profile文件
在 PostgreSQL 中,要查看所有的数据库,你可以使用 psql 命令行工具并执行一个特定的命令。以下是查看所有数据库的步骤:
打开终端:
首先,打开你的终端或命令行界面。
连接到 PostgreSQL:
使用 psql 连接到 PostgreSQL。你可以直接连接到默认数据库(通常是 postgres),或者如果你知道其他数据库的名称,也可以连接到那个数据库。但是为了查看所有数据库,我们只需要连接到任何数据库即可。
psql -U postgres 在这里,-U postgres 表示以 postgres 用户身份连接。如果这是第一次以该用户身份连接到 PostgreSQL,或者你的用户密码已更改,你可能需要输入密码。
列出所有数据库:
一旦你进入了 psql 提示符,可以输入以下命令来列出所有数据库: \l 或者,你也可以使用 SQL 查询来达到相同的效果:
SELECT datname FROM pg_database; 这个查询将从 pg_database 系统目录中检索所有数据库的名称。
退出 psql:
要退出 psql 提示符,输入 \q 然后按回车键。 如果你希望从命令行(而不是进入 psql)直接获取数据库列表,你可以使用 pg_lsclusters(如果你安装了 postgresql-common 包)或者结合使用 psql 和 bash 脚本。但是,通常 psql 的 \l 命令是最简单和最直接的方法来查看所有数据库。
探索分布式AI新纪元:Ray框架全解析 Ray是一个强大的开源框架,专为扩展人工智能(AI)和Python应用程序设计。它提供了一个核心的分布式运行时环境,并集成了多个AI库,简化了机器学习计算的过程。让我们一起深入了解Ray的魅力及其能带给你的优势。
项目介绍 Ray的核心在于提供了一种统一的方式,让你能够从本地开发环境无缝地扩展到大规模集群。无论你是进行数据处理、模型训练还是应用部署,Ray都能帮助你在各种环境中实现代码的高性能执行。
该框架包括以下关键组件:
Data:为机器学习提供的可扩展数据集。Train:分布式训练库。Tune:大规模超参数调优工具。RLlib:用于强化学习的可扩展平台。Serve:可编程且可扩展的服务层。 项目技术分析 Ray的核心技术包括任务(Tasks)、演员(Actors)和对象(Objects)。任务是无状态的函数,可以在集群中执行;演员则是有状态的工作进程,它们可以在集群中创建并共享状态;而对象则是可以在集群中跨节点访问的不可变值。这样的设计使得Ray既支持静态数据处理,又可以应对动态的、复杂的工作负载。
此外,Ray还提供了实时监控和调试的Dashboard,使开发者能够更轻松地管理和理解其在Ray上的应用和集群状态。
应用场景 Ray适用于多种应用场景,包括但不限于:
大规模数据预处理与清洗。分布式深度学习模型训练。实时超参数调整和模型优化。强化学习算法的实现与优化。高性能、可扩展的微服务架构构建。 由于其高度通用性,任何Python应用程序,无论其领域或类型,都可以通过Ray实现水平扩展。
项目特点 无缝扩展:Ray允许你在一台笔记本电脑上编写代码,然后直接将其扩展到大型集群,无需修改代码或引入额外的基础设施。灵活的抽象:任务、演员和对象的定义,让Ray可以适应不同的工作流程,无论是面向计算的任务还是存储的状态。全面的AI支持:内置的数据、训练、调参、强化学习和服务库,满足你的全方位AI需求。跨平台兼容:Ray可在任何机器、集群、云提供商以及Kubernetes上运行,并与许多社区集成无缝配合。 安装Ray非常简单,只需一行命令:pip install ray,即可开始你的分布式之旅。
想要了解更多?查看官方文档,阅读白皮书以及参与我们的社区论坛,共同探讨Ray的可能性!
Ray正在重塑AI和Python应用的未来,现在就加入我们,开启你的分布式之旅吧!
推荐使用:WebPageTest - 动态性能测试工具 项目介绍 WebPageTest 是一个强大的开放源代码性能测试平台,用于评估网站和网页应用的加载速度与性能。这个项目由 webpagetest.org 提供支持,并允许用户在全球范围内安装自己的实例,进行深度的网页性能分析。
项目技术分析 WebPageTest 基于 PHP 编写,依赖 PHPUnit 进行单元测试。项目中包含了详细的文档、变更日志以及跨平台的浏览器代理(wptagent)项目,使得整个系统具备了高度的灵活性和可扩展性。此外,它还提供了 RESTful API,方便开发者通过命令行工具如 /bulktest 和 /batchtool 执行批量测试并收集结果。
该项目采用双分支开发模式:主分支 master 使用 Polyform Shield 1.0.0 许可证,而 apache 分支则遵循更为宽松的 Apache 2.0 许可证,为不同需求的贡献者提供了选择。
在代码风格方面,WebPageTest 遵循 PSR12 PHP 标准,JavaScript 和 CSS 则使用 Prettier 进行格式化,同时还利用 Stylelint 对 CSS 进行了额外的 lint 检查。
项目及技术应用场景 WebPageTest 适用于广泛的场景:
网站优化:通过对不同地理位置、网络条件下的页面加载时间进行测量,帮助开发者找出瓶颈并优化网页性能。持续集成:可以集成到 CI/CD 流程中,确保每次部署后性能不会下降。监控服务:实时检测网站性能,及时发现并解决问题。教学与研究:学习网页性能测试原理和技术,或在性能优化研究中提供可靠的数据支持。 项目特点 全球化覆盖:除了官方站点,还可以自建实例,实现全球范围内的性能测试。灵活的测试工具:通过 REST API 支持自动化测试和结果分析,适合大规模数据采集。详尽的文档:从安装到使用,全面的技术文档使操作变得更加简单易懂。开源社区支持:活跃的社区为用户提供技术支持,不断推动项目更新和发展。 如果您关心网站性能,想要更好地理解和改善用户体验,那么 WebPageTest 将是您不可或缺的工具。无论是个人开发者还是企业团队,都能从中受益良多。现在就加入,开启您的网页性能之旅吧!
💌 所属专栏:【Git】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询!
💖 欢迎大家:这里是CSDN,我总结知识的地方,喜欢的话请三连,有问题请私信 😘 😘 😘
您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!🤩 🤩 🤩 文章目录 前言一、git fetch 参数1、介绍2、示范3、实战(1)第一种方法(2)第二种方法 总结 前言 大家好,又见面了,我是夜阑的狗🐶,本文是专栏【Git】专栏的第三十八篇文章;
这是今天学习到Git 高级篇 – 缓存远端数据命令的参数 💖💖💖,开启新的征程,记录最美好的时刻🎉,每天进步一点点。
专栏地址:【Git】 , 此专栏是我是夜阑的狗对Git,Gitee等工具使用过程的总结,希望能够加深自己的印象,以及帮助到其他的小伙伴😉😉。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
一、git fetch 参数 这里给大家推荐一个好用的 Git在线练习地址。在这练习网站里面也有自己的教程,就让我们一步一步跟着教程学习吧,记录下自己的所感所悟。前面已经简单的学习了怎么合并远程仓库,接下来就让我们看看在实际项目过程中是怎么远程跟踪分支的吧。话不多说,让我们原文再续,书接上回吧。
1、介绍 我们刚学习了 git push 的参数,很酷的 <place> 参数,还有用冒号分隔的 refspecs(<source>:<destination>)。 这些参数可以用于 git fetch 吗?
你猜中了!git fetch 的参数和 git push 极其相似。他们的概念是相同的,只是方向相反罢了(因为现在你是下载,而非上传)。让我们逐个讨论下这些概念……
<place> 参数,如果你像如下命令这样为 git fetch 设置 的话:
git fetch origin foo Git 会到远程仓库的 foo 分支上,然后获取所有本地不存在的提交,放到本地的 o/foo 上。
目 录
摘要 1 绪论 1.1 研究背景与意义 1.2相关技术介绍 1.3论文结构与章节安排 2 毕业论文管理系统需求分析 2.1 可行性分析 2.1.1 技术可行性分析 2.1.2 经济可行性分析 2.1.3 操作可行性分析 2.1.4 法律可行性分析 2.2 系统流程分析 2.2.1 数据流程 3.3.2 业务流程 2.3 系统功能分析 2.3.1 功能性分析 2.3.2 非功能性分析 2.4 系统用例分析 2.5本章小结 3 毕业论文管理系统总体设计 3.1 系统功能模块设计 3.1.1整体功能模块设计 3.1.2用户模块设计 3.1.3 在线反馈模块设计 3.1.4课题信息模块设计 3.1.5选题模块设计 3.2 数据库设计 3.2.1 数据库概念结构设计 3.2.2 数据库逻辑结构设计 3.4本章小结 4 毕业论文管理系统详细设计与实现 4.1用户功能模块 4.2管理员功能模块 5系统测试 5.1系统测试的目的 5.2 系统测试用例 5.3 系统测试结果 结论 参考文献 致 谢 摘要
在大多学校的教务管理系统中,毕业论文管理大多都是采用了人工进行管理,但是面对不断增加的生源,这样不仅工作量大,而且效率低下容易出错,更加不方便教师查阅和管理人员对其的管理。为了解决这些缺陷,在管理信息系统高速发展的现今,设计并实现一个合理的毕业论文管理系统是非常有必要的。
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
目录 系列篇章💥前言一、预训练任务类型二、模型和数据集选择三、指令微调数据处理四、全量参数微调实践学术资源加速步骤1:导入相关包步骤2:加载数据集步骤3:数据预处理步骤4:创建模型步骤5:配置训练参数步骤6:创建训练器步骤7:模型训练步骤8:模型推理 总结 前言 在自然语言处理(NLP)领域,预训练模型的应用已经越来越广泛。预训练模型通过大规模的无监督学习,能够捕捉到丰富的语言知识和上下文信息。然而,由于预训练模型通常需要大量的计算资源和时间进行训练,因此在实际使用时,我们往往需要对预训练模型进行微调,以便更好地适应特定的任务需求。本文将介绍全量参数微调的方法,以及如何在实践中进行操作。
一、预训练任务类型 1)掩码语言模型,自编码模型
将一些位置的token替换成特殊[MASK]字符,预测被替换的字符;(代表:BERT)
2)因果模型,自回归模型
将完整序列输入,基于上文的token预测下文的token;(代表:GPT)
3)序列到序列模型
采用编码器解码器的方式,预测放在解码器部分 (代表:GLM)
二、模型和数据集选择 目标:训练一个对话模型
模型:https://huggingface.co/Langboat/bloom-800m-zh
数据集:https://huggingface.co/datasets/c-s-ale/alpaca-gpt4-data-zh
三、指令微调数据处理 自回归编码指令微调数据处理过程
1)input输入构建:首先,我们将数据集中的指令(instruction),用户输入(input),以及预期输出(output)拼接成单一的字符串。这创建了一个格式为[instruction] [input] [output]的序列。
2)label标签创建:接着,为了构建训练标签,我们将用户输入部分保持不变,而对于输出部分,我们将其转化为目标标签。在自回归编码语言模型中,除了输出部分外,其他部分(包括指令和输入)的标签被替换为一个特殊的分隔符(例如:[SEP])加上-100,表示这部分不需要模型去预测。(前面instruction 和 input,对应部分不需要推理,采用-100填充;后面补上output)
四、全量参数微调实践 在自然语言处理(NLP)领域,全量参数微调(Fine-tuning)是释放预训练语言模型潜力的关键步骤。该过程涉及对大规模模型进行细微调整,以适应特定的下游任务。全量参数微调的标准流程包括:导包、加载数据集、数据预处理、创建模型、配置训练参数、创建训练器、模型训练、模型推理。
学术资源加速 方便从huggingface下载模型,这云平台autodl提供的,仅适用于autodl。
import subprocess import os result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True) output = result.stdout for line in output.splitlines(): if '=' in line: var, value = line.
文章目录 应用分层什么是MVC?什么是 SpringMVC?三层架构三层架构和MVC的关系 应用分层 在讲解什么是MVC之前,先来理解一下什么是应用分层。
应用分层是一种软件开发设计思想,将应用程序划分成N个层次,每个层次都分别负责自己的职责,多个层次之间来协同提供完整的功能,根据项目的复杂度,将项目分成三层或四层等。
举个例子:比如,一个公司创始初期,创始人要身兼数职,既要做财务,又要做人事,又要做行政,但随着公司的越来越大,就会划分成多个不同的部门。
为什么要进行应用分层???
在功能简单,代码量少是,我们通常不考虑分层,但是,随着业务越来越复杂,功能越来越强大,大量的代码都混在了一起,会出现逻辑不清晰,各模块相互依赖,代码扩展性差,改动一处牵动全身等问题,所以,就要对项目进行分层,MVC 和 三层架构 都是应用分层的充分体现,下面先看一下什么是MVC。
什么是MVC? MVC(Model View Controller),它是一种思想,他把软件系统分为 以下三部分:
Model(模型):用来处理程序中数据逻辑的部分
View(视图):在应用程序中,专门和浏览器进行交互,展示数据的资源
Contreller(控制器):可以理解成是一个分发器,来决定对于视图发来的请求,需要用哪一个模型来处理,以及处理完后需要跳回到哪一个视图,也就是用来连接视图和模型的
举个例子:
1.比如进入京东的购物页面
2.搜索手机
以上的过程,当进入京东购物网站时,这个页面就相当于是一个视图,它向我们展示了各种各样的资源,在我们搜索手机这个资源时,就会发送出一个请求,此时,这个请求会交给 控制器(Controller),控制器针对这个请求就会选择对应处理模型(Model),对这个请求进行处理,而上图的展示的手机资源的页面,就相当于是处理模型处理的结果,由控制器再将这个视图返回给我们。
再举一个简单的例子:
比如我们去餐厅吃饭,服务员就会来接待我们,服务员就会将我们点的菜写在小本本上,然后交给前台,前台再交给厨师,厨师做完之后,就会再交给前台,前台再根据这个菜确定是哪个菜单,然后再让服务员交给客人,此时,服务员帮我们写菜单就相当于是一个视图,前台就相当于是控制器,厨师就相当于是模型
什么是 SpringMVC? MVC 它是一种思想,而SpringMVC 它是将这种思想进行了实现,除此之外,SpringMVC 还是一种 Web 框架
比如,在创建 SpringBoot 项目时,所勾选的 Spring Web 框架就是SpringMVC框架,所以,可能就会产生这样的疑问:我们创建的不是SpringBoot项目吗,怎么变成了 SpringMVC 项目,它们俩之间到底有什么关系呢???
SpringBoot 和 SpringMVC 的关系
SpringBoot是2014年发布的,Spring是2004年发布的,在2014年发布之前,就不能⽤Spring实现MVC架构吗?当然不是了.
SpringBoot 只是实现 SpringMVC 的一种方式,SpringBoot 可以添加很多的依赖,借助这些依赖实现不同的功能,SpringBoot 就是通过添加 SpringWebMVC框架,来实现Web功能
举个例子:
比如做饭,我们做饭不是只能在厨房做,做饭这个事情在几千年就有了,只要有火有食材就可以做,所以做饭就比是 MVC,SpringBoot 就好比是厨房,通过在厨房里装燃气灶,装一些工具等,也可以实现做饭这个功能。
所以,如果想要实现 Web开发的话,就要引入这个 Web 框架
Spring在实现 MVC的时候,也做了一些改进:
直接把请求发给 控制器Controller,并不经过视图。就像我们去餐厅吃饭时,不需要服务员为我们记录菜单了,直接由前台记录,记录完之后交给厨师。
三层架构 现在MVC这种方式也已经不再使用了,而主流的是前后端分离,不再需要View这个模块了,不需要再关注于前端了,我们只要约定好接口,写好后端即可,所以,对于后端,也有了一种新的分层方式,就是三层架构,分为以下三层:
我的面试宝典:一线互联网大厂Java核心面试题库 以下是我个人的一些做法,希望可以给各位提供一些帮助:
整理了很长一段时间,拿来复习面试刷题非常合适,其中包括了Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等,且还会持续的更新…可star一下!
283页的Java进阶核心pdf文档
Java部分:Java基础,集合,并发,多线程,JVM,设计模式
数据结构算法:Java算法,数据结构
开源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架构设计,Redis缓存,Zookeeper,kafka,RabbitMQ,负载均衡等
微服务部分:SpringBoot,SpringCloud,Dubbo,Docker
还有源码相关的阅读学习
本文已被CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】收录
需要这份系统化的资料的朋友,可以点击这里获取
文章目录 前言一、JDK 11(Java 11)之后 JRE 说明二、选择自己需要的 JDK 版本三、对下载的 JDK 进行解压四、执行 Dos 命令生成 JRE总结 前言 我们之前的 JDK 1.8 版本乃至以下版本压缩包下载解压后直接运行会生成 JDK、JRE 两个目录文件,但从 Java 11 之后,只有 JDK 目录文件生成,没有单独的 JRE 目录文件,这时有需要的同学就可以通过命令行的方式手动生成 JRE。
一、JDK 11(Java 11)之后 JRE 说明 在 JDK 11(Java 11)之后 JRE 是集成在 JDK 之中的,无需我们额外进行环境变量配置,仅需配置 JDK 的 JAVA_HOME 与 Path 变量即可。
JAVA_HOME 变量指向 JDK 根目录,即 bin 目录上一级。PATH 变量指向 JDK 的 bin 目录。 如果切实需要 JRE 的同学或者是了解如何生成 JRE 目录的同学可以参考本文内容。