配置文件密码加密的3种方案 一.配置文件添加jasypt 1.pom.xml添加jasypt引用 <dependency> <groupId>com.github.ulisesbocchio</groupId> <artifactId>jasypt-spring-boot-starter</artifactId> </dependency> 2.在springboot配置文件内加入 jasypt配置 jasypt: encryptor: algorithm: PBEWithMD5AndDES ##盐 password: dddda123 #密钥 二.使用配置类初始加载加解密 1.pom.xml添加jasypt依赖 <dependency> <groupId>com.github.ulisesbocchio</groupId> <artifactId>jasypt-spring-boot-starter</artifactId> </dependency> 2.编写配置类加载bean package com.top.common.config; import org.jasypt.encryption.StringEncryptor; import org.jasypt.encryption.pbe.PooledPBEStringEncryptor; import org.jasypt.encryption.pbe.config.SimpleStringPBEConfig; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; */ /** * @author * @date 2023/6/719:41 * @Package * @description 自动配置加密信息 *//* @Configuration public class EncryptorConfig { @Bean("jasyptStringEncryptor") public StringEncryptor jasyptStringEncryptor() { PooledPBEStringEncryptor encryptor = new PooledPBEStringEncryptor(); SimpleStringPBEConfig config = new SimpleStringPBEConfig(); config.
✨✨ 欢迎大家来到贝蒂大讲堂✨✨
🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:数据结构与算法
贝蒂的主页:Betty’s blog
1. 什么是字符串匹配算法 字符串匹配是计算机科学中的一个基础概念,广泛应用于文本处理、数据挖掘、搜索引擎等领域。它的目的是在一个给定的文本串中寻找指定子串是否存在。由此,衍生了一系列的算法(如BF,BM,RK,KMP)就是我们的字符串匹配算法。
下面我们将选取两个最经典的BF与KMP算法为大家演示。
2. BF算法 2.1. 算法原理 BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。
-------以上摘自百度百科
2.2. 图例演示 上面的文字可能过于抽象,我们可以通过图示来为大家演示一下算法流程。
假设我们有两个字符串,分别记为s1与s2。其中s1是主串,s2为子串,即从s1中匹配s2。
第一步都从字符串的起始位置开始匹配。 相等则继续匹配,否则从s1的下一个位置重新开始匹配。然后一直重复上述过程。 这里我们就需要思考一个问题,匹配失败如何返回s1的下一个位置重新匹配。其实特别简单,我们要知道j下标如果从零开始就代表成功匹配的个数。我们只需让i下标减去j下标就会回到原来的起始位置,这是再加1就是我们下一次匹配的开始位置。 起始位置1与i下标之间的元素个数就是j下标与起始位置2之间的个数。所以i-起始位置1=j-起始位置2=>起始位置1=i-j。 最后当j移动至末尾证明匹配成功,返回s1成功的匹配成功的起始下标。当i移动到末尾时,匹配失败返回-1。 2.3. 代码实现 下面是具体的代码实现,其中串是以顺序串的形式实现。
int BF(Sstring* s1, Sstring* s2) { assert(s1 && s2); int len1 = StrLength(s1); int len2 = StrLength(s2); if (len1 == 0 || len2 == 0) { return -1; } int i = 0;//主串下标 int j = 0;//子串下标 while (i < len1 && j < len2) { if (s1->data[i] == s2->data[j])//匹配成功 { i++; j++; } else { j = 0; i = i - j + 1; } } if (j >= len2)//匹配失败 { return i - j; } return -1; } 2.
1.下载nw 下载 NW.js(官网:NW.js),选择normal的即可,下载完成之后解压。
2.导入web项目 2.1解压后的文件夹如下图所示,其中myapp(名字随便起)里面放的是自己的前端项目。
2.2myapp示例内容如下(实际就是一个web的项目文件)
2.3package.json可以理解为应用的配置文件,是必须要有的;index.html作为应用的入口文件,内容和一般网页类似,名字可以按自己喜好起,但是一定要和配置中的“main”参数设置一致;
2.4其中window里面配置的是程序执行后的窗口配置,相关参数如下所示:
title : 字符串,设置默认 title。width/height : 主窗口的大小。toolbar : bool 值。是否显示导航栏。icon : 窗口的 icon。position :字符串。窗口打开时的位置,可以设置为“null”、“center”或者“mouse”。min_width/min_height : 窗口的最小值。max_width/max_height : 窗口显示的最大值。resizable : bool 值。是否允许调整窗口大小。always-on-top : bool 值。窗口置顶。fullscreen : bool 值。是否全屏显示。show_in_taskbar : 是否在任务栏显示图标。frame : bool 值。如果设置为 false,程序将无边框显示。"chromium-args" :"-allow-file-access-from-files" 相当于给谷歌浏览器添加启动参数一样,这行代码允许angularjs直接访问本地json文件。 3.运行程序 将应用程序目录拖放到nw.exe即可运行;
4.打包成exe文件 将myapp里面的文件压缩成zip文件,然后将文件名改成app.nw;将app.nw放在和nw.exe同一个目录下(即最外层);从nw.exe文件所在的目录进入cmd控制台,执行以下命令; copy /b nw.exe+app.nw app.exe 然后就出现了app.exe可执行文件可以新建一个文件夹,把必须的文件放里面,如下为app.exe执行必须的文件: 生成app.exe文件之后,将多余的文件删除,保留上面这些文件即可,上面这些文件是app.exe执行所需要的必须的文件;
至此,nw.js将web程序打包成exe可执行文件结束。
探索 Pure-Python ADB: 全新视角下的安卓设备管理 pure-python-adbThis is pure-python implementation of the ADB client.项目地址:https://gitcode.com/gh_mirrors/pu/pure-python-adb 在移动开发领域,Android Debug Bridge (ADB) 是一个不可或缺的工具,它允许开发者与Android设备进行交互,包括安装应用、调试、文件传输等功能。然而,原生的ADB是基于C++实现的,对于一些对Python更熟悉的用户来说,可能需要一个更加亲和的版本。这就是 的诞生背景。
项目简介 Pure-Python ADB 是一个全Python编写的ADB实现,由开发者 Swind 创建并维护。它的主要目标是在保持与原生ADB功能一致的同时,提供一个纯Python接口,使得更多的Python开发者可以轻松地在自己的项目中集成ADB功能,无需了解底层的C++代码。
技术分析 完全用Python编写:
这意味着你可以利用Python的丰富库和强大的社区支持,为ADB操作添加更多的定制化功能。对于那些不熟悉C++的开发者来说,理解代码和贡献变得更简单。 兼容性:
Pure-Python ADB 兼容了原生ADB的所有核心命令,如shell, push, pull, install等,确保你能无缝迁移。 易用性:
提供了简洁明了的API,使开发者能够快速上手,例如通过一行代码就能执行shell命令: from pure_python_adb.adb import Adb adb = Adb() output = adb.shell('getprop ro.build.version.release') print(output) 模块化设计:
源码结构清晰,易于扩展和维护,可以根据需求选择使用特定的部分。 跨平台:
基于Python的特性,该库可以在任何Python支持的操作系统(包括Windows, macOS, Linux)上运行。 应用场景 自动化测试:集成到你的自动化测试框架中,方便地控制设备状态,如启动应用、模拟点击等。设备监控:收集设备的性能数据,如CPU利用率、内存使用情况等。应用部署:批量安装或更新应用程序,特别适合团队协作或CI/CD流程。日志分析:从设备获取日志信息,帮助调试或故障排查。 特点 简洁的API:Pythonic的语法设计,让ADB操作变得直观且高效。轻量级:相比于原生的ADB,体积小,依赖少,易于集成。可自定义:因为是开源的,可以根据具体需求进行二次开发和扩展。 总的来说,Pure-Python ADB 以Python语言重新构建了ADB的交互方式,提供了一个更加友好、灵活的接口,让开发者能更高效地管理工作中的Android设备。如果你是一名Python爱好者,并且在寻找一个便于集成的ADB解决方案,那么 Pure-Python ADB 绝对值得尝试!立即前往项目GitHub仓库,开始探索吧!
pure-python-adbThis is pure-python implementation of the ADB client.
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 1-安装Andaconda2-在Anaconda Prompt中安装PySpark3-执行安装4-使用Pycharm构建Project(准备工作)需要配置anaconda的环境变量–参考课件需要配置hadoop3.3.0的安装包,里面有winutils,防止pycharm写代码的过程中报错 补充:
PyCharm构建Python project
项目规划项目名称:Bigdata25-pyspark_3.1.2模块名称:PySpark-SparkBase_3.1.2,PySpark-SparkCore_3.1.2,PySpark-SparkSQL_3.1.2文件夹:main pyspark的代码data 数据文件config 配置文件test 常见python测试代码放在test中 应用入口:SparkContext
http://spark.apache.org/docs/latest/rdd-programming-guide.html WordCount代码实战
需求:给你一个文本文件,统计出单词的数量算子:rdd的api的操作,就是算子,flatMap扁平化算子,map转换算子Transformation算子Action算子步骤:1-首先创建SparkContext上下文环境
2-从外部文件数据源读取数据
3-执行flatmap执行扁平化操作
4-执行map转化操作,得到(word,1)
5-reduceByKey将相同Key的Value数据累加操作
6-将结果输出到文件系统或打印代码: # -*- coding: utf-8 -*- # Program function: Spark的第一个程序 # 1-思考:sparkconf和sparkcontext从哪里导保 # 2-如何理解算子?Spark中算子有2种, # 一种称之为Transformation算子(flatMapRDD-mapRDD-reduceBykeyRDD), # 一种称之为Action算子(输出到控制台,或文件系统或hdfs),比如collect或saveAsTextFile都是Action算子 from pyspark import SparkConf,SparkContext if __name__ == '__main__': # 1 - 首先创建SparkContext上下文环境 conf = SparkConf().setAppName("FirstSpark").setMaster("local[*]") sc = SparkContext(conf=conf) sc.setLogLevel("WARN")#日志输出级别 # 2 - 从外部文件数据源读取数据 fileRDD = sc.
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 4)设置 DataFrame 的行标签
# 注意:DataFrame设置行标签时,并不会改变原来的DataFrame,而是返回的副本 china_df = china.set_index('year') 3.2 DataFrame 的行位置编号和列位置编号 DataFrame 除了行标签和列标签之外,还具有行列位置编号。
行位置编号:从上到下,第1行编号为0,第二行编号为1,…,第n行编号为n-1
列位置编号:从左到右,第1列编号为0,第二列编号为1,…,第n列编号为n-1
注意:默认情况下,行标签和行位置编号是一样的。
4. DataFrame 获取指定行列的数据 以下示例都使用加载的 gapminder.tsv 数据集进行操作,注意将 year 这一列设置为行标签。
4.1 loc函数获取指定行列的数据 基本格式:
语法说明df.loc[[行标签1, ...], [列标签1, ...]]根据行标签和列标签获取对应行的对应 列的数据,结果为:DataFramedf.loc[[行标签1, ...]]根据行标签获取对应行的所有列的数据 结果为:DataFramedf.loc[:, [列标签1, ...]]根据列标签获取所有行的对应列的数据 结果为:DataFramedf.loc[行标签]1)如果结果只有一行,结果为:Series 2)如果结果有多行,结果为:DataFramedf.loc[[行标签]]无论结果是一行还是多行,结果为DataFramedf.loc[[行标签], 列标签]1)如果结果只有一列,结果为:Series, 行标签作为 Series 的索引标签 2)如果结果有多列,结果为:DataFramedf.loc[行标签, [列标签]]1)如果结果只有一行,结果为:Series, 列标签作为 Series 的索引标签 2)如果结果有多行,结果为DataFramedf.loc[行标签, 列标签]1)如果结果只有一行一列,结果为单个值 2)如果结果有多行一列,结果为:Series, 行标签作为 Series 的索引标签 3)如果结果有一行多列,结果为:Series, 列标签作为 Series 的索引标签 4)如果结果有多行多列,结果为:DataFrame 演示示例:
示例1:获取行标签为 1952, 1962, 1972 行的 country、pop、gdpPercap 列的数据 示例2:获取行标签为 1952, 1962, 1972 行的所有列的数据 示例3:获取所有行的 country、pop、gdpPercap 列的数据 示例4:获取行标签为 1957 行的所有列的数据 示例5:获取行标签为 1957 行的 lifeExp 列的数据 示例实现:
你还在为写不出公文而烦恼吗?公文写作在职场交流中扮演着至关重要的角色。很多人无法写出高质量公文文本,看到公文写作头疼不已。小编给你推荐6款功能强大的AI公文写作辅助工具,无论是需要撰写报告、计划书,还是各类正式文件,这些工具通过 AI 帮助你迅速生成结构严谨、内容精确的专业文档。
01晓语台
网址:晓语台-先进的点击式文本创作平台!晓语台,是一款基于大语言模型、混合大模型和AIGC技术研发的智能创作平台。创作能力主要围绕营销文本的AI创作,覆盖了行业、平台、职业等不同场景500余款创作主题,旨在助力企业与自媒体人便捷高效的获取内容创作灵感和营销物料。https://www.xiaoyutai.com/
晓语台是一个专注文本创作平台,提供在线协作、自由扩写、自由润色、自由改写,覆盖了品牌与市调、商业媒体、社交媒体、搜索营销、数字广告、职场办公共六类全营销文本高维创作场景。
02新华妙笔
网址: 新华妙笔-AI公文写作平台新华妙笔,AI公文写作学习平台,由新华社媒体融合生产技术与系统国家重点实验室与博特智能公司联合研发。集查、写、审、问、学一体,集合了范文参考资料、写作素材、智能写作、校对纠错、润色续写等特色功能。帮助公务员、事业单位人员、国企人员的机关公文写作场景,快速拟稿,降低内容风险,擅长工作总结、竞聘材料、发言稿、工作简报等材料等智能写作。https://miaobi.xinhuaskl.com/
新华妙笔是一款专业的AI公文写作平台,由新华通讯社与博特智能共同研发推出,集成了案例参考、材料查找、AI写作、修改润色、审核校对、文件学习等功能,全方位地辅助公职人员提高创作效率,节省人工编写的时间和精力。
03逐笔AI公文写作
网址: 逐笔公文写作ai-公文写作神器-国内领先的AI智能创作平台欢迎来到逐笔公文写作ai,国内领先的AI智能创作平台!我们为您提供高效、准确的公文写作解决方案。通过我们的人工智能技术,您可以轻松、快速地撰写各种公文,无论是公告、报告还是信函。无论您是企业、政府机构还是个人用户,我们都能够满足您的写作需求。尽快体验逐笔公文写作ai,开启您的智能写作之旅吧!https://zhubiai.com/template
逐笔AI公文写作——国内遥遥领先的智能AI创作平台,体制内人员的公文神器,专业解决各类写材料难题。无论是心得体会、总结汇报、演讲发言还是金句写作,都能为你统统搞定。不仅如此,还内置了专业体制公文库,精品文稿每日上新,为你的写作提供源源不绝的灵感源泉。
04星火公文写作助手
网址: 讯飞星火公文助手-官方网站讯飞星火公文助手,一款依托于科大讯飞星火大模型技术的AI公文写作助手。星火公文助手提供素材筹备、拟稿写作和审稿核稿等功能,专为广大公文材料撰稿人打造,使用简单便捷高效。https://gw.iflydocs.com/#/dashboard
科大讯飞人工智推出的生成式写作工具,星火公文写作助手 、星火公文写作助手 、星火公文写作助手 适用于述职总结、心得体会、发言稿、工作简报等材料写作。
05蛙蛙写作
网址: 蛙蛙写作——超级AI智能写作助手蛙蛙写作是一款智能AI写作工具,提供公众号写作,工作报告,学术论文,ppt,演讲稿,简历润色,活动策划,旅游攻略,好物种草,短视频脚本创作,AI智能续写扩写等服务。为专业小说作者、自媒体运营者等内容生产者,帮助提升写作速度、优化创作模式、突破内容生产力瓶颈。https://www.wawawriter.com/
蛙蛙写作软件是一款功能非常强大的智能写作助手,蛙蛙写作app让大家可以轻松的进行写作创作,平台里面包含的功能很全面,满足大家的写作创作需要
06 小莫写作
网址: 小莫写作-文章写作神器-AI写作工具小莫写作是新一代AI写作辅助工具,包含提纲推荐、内容编写、智能续写、智能改写、文本纠错、文章查重等功能。https://www.xiaomo.com/
小莫写作是一款基于人工智能的AI论文写作辅助工具,可以帮助用户快速生成论文提纲、内容、参考文献等,还可以进行论文查重、改写、纠错等操作,是学生和老师的好帮手。
近年来,Python在编程语言界赚得盆满钵满,无论是人气还是薪资,相应的,对Python岗位的要求也越来越高。无论你是零基础还是老前辈,对于python基础都不能掉以轻心。
今天给大家分享一百多道Python真题的合集,都是经典题,从易到难,非常全面,供大家参考和学习。答案都是需要对应,代码齐全。它们不仅可以作为练习,也可以作为面试的参考。建议人手一份。
目录
实例001:数字组合
实例002:“个税计算”
实例003:完全平方数
实例004:这天第几天
实例005:三数排序
实例006:斐波那契数列
实例007:copy
实例008:九九乘法表
实例009:暂停一秒输出
实例010:给人看的时间
实例011:养兔子
实例012:100到200的素数
实例013:所有水仙花数
实例014:分解质因数
实例015:分数归档
实例016:输出日期
实例017:字符串构成
实例018:复读机相加
实例019:完数
实例020:高空抛物
实例021:猴子偷桃
实例022:比赛对手
实例023:画菱形
实例024:斐波那契数列II
实例025:阶乘求和
实例026:递归求阶乘
实例027:递归输出
实例028:递归求等差数列
实例029:反向输出
实例030:回文数
实例031:字母识词
实例032:反向输出II
实例033:列表转字符串
实例034:调用函数
实例035:设置输出颜色
实例036:算素数
实例037:排序
实例038:矩阵对角线之和
实例039:有序列表插入元素
实例040:逆序列表
实例041:类的方法与变量
实例042:变量作用域
实例043:作用域、类的方法与变量
实例044:矩阵相加
实例045:求和
实例046:打破循环
实例047:函数交换变量
实例048:数字比大小
实例049:lambda
实例050:随机数
实例051:按位与
实例052:按位或
实例053:按位异或
实例054:位取反、位移动
实例055:按位取反
实例056:画圈
实例057:画线
实例058:画矩形
实例059:画图(丑)
实例060:字符串长度
实例061:杨辉三角
实例062:查找字符串
实例063:画椭圆
实例064:画椭圆、矩形
实例065:画组合图形
实例066:三数排序
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 print(each.get_type())  里面的判断逻辑也是根据 Keyword.DML和Keyword.DDL来判断的。根据第一次获取到的token来判断。有了get\_type那么我们要实现的SQL解析的第一步已经有了,首先就可以确定这个SQL的功能与用户的读写查改权限匹配了。先不急我们还需要知道如何解析成一颗树。 ## 二、基类-TokenList 这个类就相当的大了,也正是我们了解解析成AST抽象解析树的关键所在了。源码就不贴上去可太多了,主要找一些能够改写使用到的方法即可。 该类继承Token,而Statement就是继承的此类,也就是Statement最终继承的此两者全部方法。 query = ‘CREATE TABLE AS Select a, col_2 as b from Table_A;select * from foo’
stmt=sqlparse.parse(query)
stmt_1=stmt[0].tokens
#for each_token in stmt_1:
#print(each_token)
sqlparse.sql.TokenList(stmt_1)._get_repr_name()
stmt[0]._get_repr_name()
### 1. \_get\_repr\_name()方法 将输出自身数据结构: def _get_repr_name(self):
return type(self).name
### 2.\_pprint\_tree()方法 这里有关树的解析在这个打印\_pprint\_tree函数上面: def _pprint_tree(self, max_depth=None, depth=0, f=None, _pre=‘’):
“”“Pretty-print the object tree.”“”
token_count = len(self.tokens)
for idx, token in enumerate(self.tokens):
前端vscode必备插件 一、基础的Auto Rename Tag⭐Code Runner⭐CSS PeekDotENVError Lens⭐ESLintGitLens — Git supercharged⭐jsdocopen in browserPath Intellisense⭐Prettier - Code formatterSmart ClickGitHub Copilot⭐⭐Turbo Console Logvscode extension for EChartsi18n Ally⭐Tailwind CSS IntelliSense⭐vue-helperJSON to TS 二、Vue相关的Vue - Official ⭐⭐⭐~~Vue Language Features (Volar)⭐⭐⭐~~~~TypeScript Vue Plugin (Volar)~~Vue 3 SnippetsVue VSCode Snippetsvue-component 三、美化Material Icon Theme⭐Vitesse Theme⭐⭐⭐ 一、基础的 Auto Rename Tag⭐ 插件地址
修改标签会同步修改
Code Runner⭐ 插件地址
快速运行 调试js
CSS Peek 插件地址
跳转对应 css
DotENV 插件地址
高亮ENV文件
Error Lens⭐ 插件地址
实时显示错误
环境: Topaz Video AI 5.0
问题描述: 如何将低分辨率的视频变高清,使用AI工具分辨率画质增强至1080P、4K或者8K
原视频
增强1080P
解决方案: 1.打开软件,导入要处理的视频(工具在本文最后附上)
2.右侧选择输出参数
Resolution选择输出方案1080P 60帧
3.最后右下角点击导出
导出期间会自动下载所需要模型
4.处理好效果
原视频画质
处理后导出画质
PJ操作,把程序放在主程序安装界面
工具下载
🐇明明跟你说过:个人主页
🏅个人专栏:《Kubernetes航线图:从船长到K8s掌舵者》 🏅
🔖行路有良友,便是天堂🔖
目录
一、前言
1、什么是负载均衡
2、负载均衡的应用场景 3、负载均衡的目标
二、负载均衡基本原理 1、负载均衡的分类
2、负载均衡的核心组件与工作流程
三、负载均衡算法
1、轮询算法(Round Robin)
2、加权轮询算法(Weighted Round Robin) 3、最少连接数算法(Least Connections) 4、响应时间算法(Response Time) 5、哈希算法(Hashing) 四、负载均衡策略与实现方式
1、本地负载均衡与全局负载均衡 2、DNS负载均衡
3、反向代理负载均衡
4、IP层负载均衡
5、应用层负载均衡
五、负载均衡技术的前沿发展
1、容器化与云原生时代的负载均衡
2、人工智能在负载均衡中的应用 3、边缘计算在负载均衡中的角色 一、前言 1、什么是负载均衡 在互联网中,负载均衡(Load Balancing)是一种网络技术或策略,用于将网络请求或数据流分配到多个服务器或网络设备上,从而确保资源的有效利用、优化性能,并提高系统的可靠性和容错能力。
负载均衡广泛用于各种场景,如Web服务器集群、数据库集群、CDN(内容分发网络)等。通过使用负载均衡技术,企业可以构建出高性能、高可靠性的互联网应用和服务。
2、负载均衡的应用场景 Web服务器负载均衡: 在 Web 服务器集群中,负载均衡用于分发来自用户的请求到不同的服务器上,以确保各个服务器的负载相对均衡,提高整个系统的性能和可用性。数据库负载均衡: 对于高并发的数据库系统,负载均衡可以用于分发查询请求到不同的数据库节点上,以减轻单个数据库节点的压力,提高系统的响应速度和并发能力。应用服务器负载均衡: 在分布式应用系统中,负载均衡可以用于分发应用程序的请求到不同的应用服务器上,以实现应用程序的水平扩展和负载均衡,提高系统的性能和可伸缩性。缓存服务器负载均衡: 对于缓存服务器集群,负载均衡可以用于分发读取请求到不同的缓存节点上,以提高缓存命中率和系统的性能。
3、负载均衡的目标 性能优化:通过分散请求到多个服务器,减少单个服务器的负载,从而提高整体性能。高可用性:当某个服务器或网络设备发生故障时,负载均衡器可以自动将请求重定向到其他正常运行的服务器上,确保服务的连续性和可用性。资源利用:通过合理分配请求,确保所有服务器都能得到充分利用,避免资源的浪费。 二、负载均衡基本原理 1、负载均衡的分类 负载均衡可以根据其实现方式和部署方式进行分类,主要包括硬件负载均衡和软件负载均衡。
硬件负载均衡:
特点:硬件负载均衡器通常是专门设计的物理设备,具有高性能、高可靠性和高可用性,能够处理大规模的并发请求和高速数据流量。优势:性能稳定、可靠性高、支持大规模并发、具有专业的技术支持和维护。缺点:成本较高、部署和配置相对复杂、灵活性较差。 软件负载均衡:
特点:软件负载均衡器是基于软件实现的负载均衡解决方案,运行在通用的服务器或虚拟机上,通常采用分布式架构和集群部署。优势:成本较低、部署和配置灵活、易于扩展和定制、可在普通硬件上运行。缺点:性能和可靠性可能不如硬件负载均衡器、需要自行管理和维护、对系统资源的消耗较大。 根据部署方式的不同,软件负载均衡又可以分为以下几种类型:
应用层负载均衡:在应用层(如 HTTP、HTTPS)进行负载均衡,通常采用反向代理服务器或应用程序级别的负载均衡器,如 Nginx、HAProxy、Apache 等。网络层负载均衡:在网络层(如 TCP、UDP)进行负载均衡,通常通过网络设备或软件实现,如 IPVS、LVS、Keepalived 等。DNS 负载均衡:通过 DNS 解析将请求分发到不同的服务器上,通常采用 DNS 服务器配置多个 A 记录或 CNAME 记录来实现。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)
正文 2.这个话题让分开来谈优点,其实没太有必要。个人觉得都半斤八两。这里稍微的提一提吧,ChatGPT相对其他的GPT在编程领域,在针对用户提出的技术问题时候,会稍微精确一些,但是总体区别不大。 3.ChatGPT起步比文心一言,但是市场定位错误,让ChatGPT失掉了很多先机。相反把先机变成流失客户群体的一步“错棋”。 GPT在国外爆火以后,国内各路小神仙小诸侯纷纷迎战,纷纷出品了抄袭模式,并且都有一个免费使用n次,再用就冲会员的模式,太着急套现。 ChatGPT竟然目光狭窄的也走了类似的套路,每日限流,在技术不准确交互内容不清晰的情况下,限定了体验次数。纷纷败坏了一大批用户的”好奇心“。我就是体验过几天之后,基本不存有好感。 抓着方向二:文心一言 那会的体验感受 1.说到”文心一言“,就不得不说一下”科大讯飞“的GPT。科大讯飞在技术相对稳定之后,邀请各路用户免费申请用户资质。要是到,这个场景:当时很多人,都对GPT跃跃欲试,但是很多小GPT网站让大家很挠头!免费测试N个问题,刚刚要过把瘾,痛快的玩玩人机交互,【请充值】纷纷扫兴!科大讯飞的模式吸引了大批的用户来战!并且使用效果都不错,很快的抓住了一大把用户。重点是:申请就能无线用,没有充值的脏窗口。再使用效果不错情况下,并且不限数量使用很快市场定位稳定。 2.就在”科大讯飞”如火如荼的几天后,百度首页突然莫名的多了一个小链接地址“文心一言”。是的它前期是没做任何宣传就上线的。而且,惊人的发现“科大讯飞”与“文心一言”的问题回答相似度90%以上。再然后,才在其他媒体渠道上看到了"文心一言"的宣传推荐。在体验不错的情况下,它推出上线了APP。虽然“ChatGPT”失去了先机,“科大讯飞”抓住了,但是百度的便捷和强大的用户群让文言一心占据了主导。 3.目前GPT仍存在很多不尽人意的地方,而且很多很多。ChatGPT要做的还有很多很多。回答很多时候驴唇不对马嘴,图片处理很多都在胡乱应付,语音交互不尽人意… 方向三:对人工智能的看法
从技术领域和我们现有发展,GPT这点目前市场公布功能,距离人工智能成熟或者是实际投产,路途还很遥远。
从目前公布的GPT技术来看,我们的GPT不客气的说,就是在抄袭,没有创新。我们GPT的发展水平距离GPT的真是水平差距是很大很大。我们要做的事儿还有很多。
言辞多有犀利,一家之言。共勉! 最全的Linux教程,Linux从入门到精通
======================
linux从入门到精通(第2版)
Linux系统移植
Linux驱动开发入门与实战
LINUX 系统移植 第2版
Linux开源网络全栈详解 从DPDK到OpenFlow
第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。
本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
AqOAP-1713308104681)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 source /etc/proflie 进入zookeeper创建data文件夹
mkdir data 进入data
cd data vim myid 写入2
2 然后在进入zookeeper的conf下
修改zoo_sample.cfg名字改为zoo.cfg
mv zoo_sample.cfg zoo.cfg 修改zoo.cfg
vim zoo.cfg 添加
server.2=bigdata1:2888:3888 server.3=bigdata2:2888:3888 server.4=bigdata3:2888:3888 修改
dataDir=/opt/module/zookeeper-3.5.7/data 分发zookeeper
scp -r /opt/module/zookeeper-3.5.7/ root@bigdata2:/opt/module/ scp -r /opt/module/zookeeper-3.5.7/ root@bigdata3:/opt/module/ 修改bigdata2和bigdata3中的zookeeper下的data中myid的值分别改为3和4
与下方的对应
server.2=bigdata1:2888:3888 server.3=bigdata2:2888:3888 server.4=bigdata3:2888:3888 修改名称使环境变量里的和module下的一致
在module下:
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7 mv kafka_2.12-2.4.1 kafka-2.12 启动zookeeper
三台都启动
启动后jps查看进程 QuorumPeerMain
zkServer.sh start 配置好kafka的环境变量
三台都配
vim /etc/profile #kafka export KAFKA_HOME=/opt/module/kafka-2.12 export PATH=$PATH:$KAFKA_HOME/bin 刷新环境变量
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 实现过程
代码展示
主框架
棋子类
棋盘类
项目结构
总结
效果展示 一、游戏界面 0c8ef08d320c4128954c66b729d7da12.png 二、悔棋与重开功能 项目介绍 五子棋是一种两人对弈的纯策略型棋类游戏,亦称串珠连,五子是中国民间非常熟知的一个古老棋种,它因操作简单、逻辑性强,深受喜爱,本项目基于Java技术,开发了一个操作简单、界面简洁、功能较完整的“五子棋”游戏。通过本游戏的开发,达到初学者学习和熟悉软件开发流程的目的。
总体需求 本程序主要完成五子棋游戏的简单操作,用户通过鼠标完成游戏过程。需要满足以下几点要求:
1.实现五子棋简易窗口界面。
2.实现黑白棋轮流下棋功能。
3.实现自动判断获胜方功能。
4.实现悔棋与重开游戏功能。
实现过程 1.绘制窗体对象。
2.UI设计(包括游戏区域、黑白棋子、按钮和标题区域)。
3.使用鼠标监听事件实现下棋。
4.连成五子判定获胜的实现。
代码展示 主框架 在主框架里有面板对象和两个按钮对象,分别是重新开始游戏按钮,悔棋按钮。还设置一个按钮事件类,用来监听两个按钮,并作出相应的动作,代码如下:
import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import javax.swing.*; public class ChessJFrame extends JFrame { private ChessBord chessbord;//声明一个棋盘对象 private Panel tool; //声明一个面板对象 private Button StartButton;//声明开始按钮 private Button BackButton;//声明悔棋按钮 private Button exitButton;//声明退出按钮 public ChessJFrame() {//构造函数 setTitle("单机版五子棋");//设置标题 MyButtonLister mb=new MyButtonLister();//按钮事件处理对象 tool=new Panel();//面板对象 chessbord=new ChessBord();//棋盘对象 StartButton=new Button("
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 百度网盘提供各个版本链接,以及IDEA软件免费永久试用方法,Typora[2022]免费永久试用方法,以及settings.xml配置文件(下面会用到,可复制,也可以自己配置)
链接:https://pan.baidu.com/s/1wQ3o_nVtfKkLHClba60lUw?pwd=71ag
提取码:71ag
☢JDK配置 此电脑右键属性——点击右边的高级系统配置——点击环境变量——配置系统环境变量
首先配置系统变量,此处的变量名为JAVA_HOME 值为JKD安装路径 此处注意大小写 %JAVA_HOME%\bin
出现如下版本信息则说明jdk环境变量配置成功,否则检查环境变量此处应该看java version 1.8.0.251 那一行 此处截图有误 ☢Maven项目创建 💨配置maven环境变量 首先配置Maven环境变量,方法同配置jkd相同MAVEN_HOME 的值 选择 apache-maven-3.6.3-bin 目录下的 apache-maven-3.6.3 如下显示Apache-maven3.8.6 则为成功 💨配置maven settings.xml文件 可以直接把百度网盘xml文件直接复制过去覆盖如果自己配置的话,需要注意每一对标签是否缺失 <?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd"> <!-- Maven仓库地址,也就是创建的库文件目录里面的地址 --> <localRepository>D:\Eclipse\apache-maven-3.6.3-bin\apache-maven-3.6.3\maven-repo</localRepository> <!-- 下载地址更改为阿里云 --> <mirrors> <!-- 阿里云镜像 --> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>https://maven.aliyun.com/repository/public</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> <!-- 说明jdk版本 --> </profiles> <profile> <id>jdk-1.8</id> <activation> <activeByDefault>true</activeByDefault> <jdk>1.
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 defense_max int comment '最大物防', attack_range string comment '攻击范围', role_main string comment '主要定位', role_assist string comment '次要定位' ) comment ‘射手表’
row format delimited fields terminated by ‘\t’;
2.2上传(6个)源文件到该hive表的HDFS路径下
 ##### 3.查询数据 select * from t_all_hero;
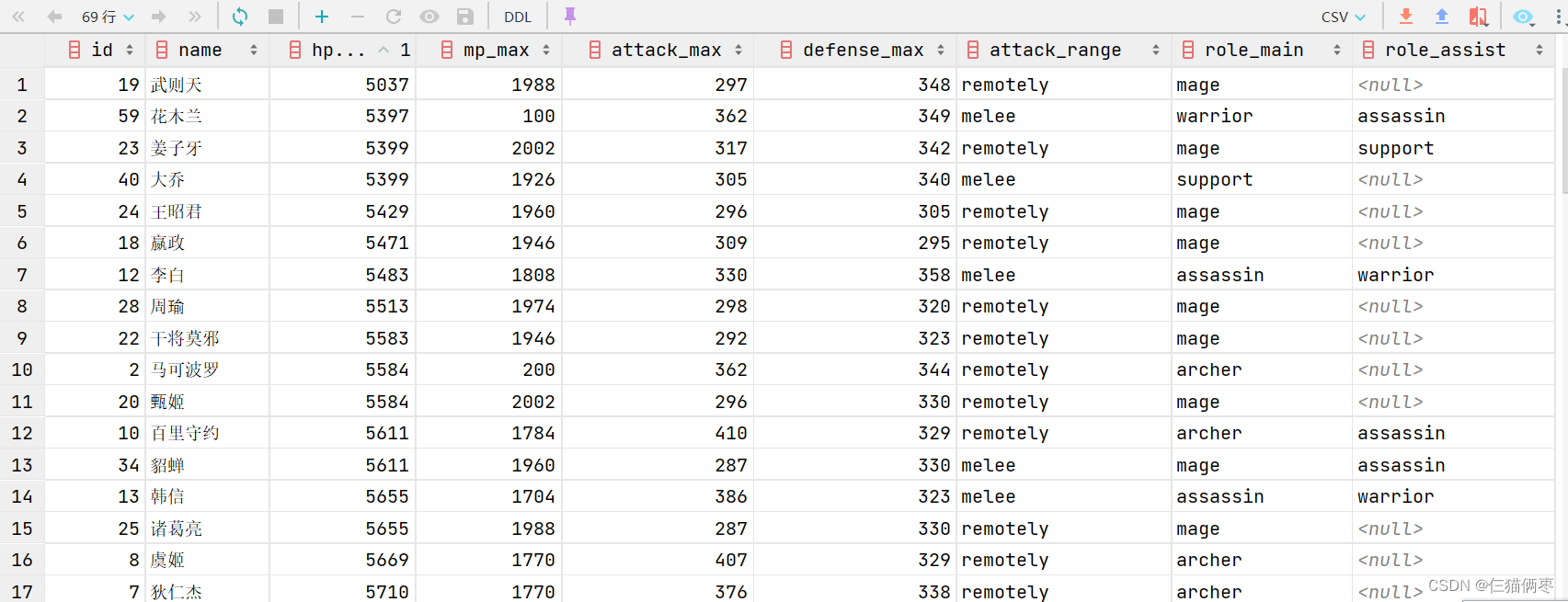 3.1查询出所有的archer数据 select * from t_all_hero where role_main=‘archer’;
问:虽然我们实现了需求, 但是需要进行全表扫描, 如何精准的获取到我们想要的数据呢?
答:可以采用分区表的思路来管理, 把各个职业的数据放到不同的文件夹中即可
##### 4.创建分区数据表 – 1. 创建分区表, 指定分区字段.
create table t_all_hero_part(
id int comment ‘ID’,
name string comment ‘英雄’,
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)
正文 显示:
java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
tzdata-java-2016g-2.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
3、卸载openjdk
[root@localhost software]# rpm -e --nodeps tzdata-java-2016g-2.el7.noarch
[root@localhost software]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
[root@localhost software]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
[root@localhost software]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
[root@localhost software]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
或者使用
[root@localhost jvm]# yum remove *openjdk*
之后再次输入rpm -qa | grep java 查看卸载情况:
[root@localhost software]# rpm -qa | grep java
python-javapackages-3.4.1-11.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
4、安装新的jdk
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文 3、启用检查点 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 启用 Checkpoint 每 5 秒 一次,模式为 EXACTLY_ONCE env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE); 4、常用配置参数 1)最终检查点 // 最终检查点,1.15开始,默认是true configuration.set(ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, false); 2)开启 Changelog // 要求checkpoint的最大并发必须为1 env.enableChangelogStateBackend(true); 3)代码中用到HDFS,需要导入hadoop依赖、指定访问HDFS的用户名 System.setProperty("HADOOP_USER_NAME", "HADOOP"); 4)开启非对齐检查点(barrier非对齐) // 开启的要求: Checkpoint模式必须是精准一次,最大并发必须设为1 checkpointConfig.enableUnalignedCheckpoints(); // 开启非对齐检查点才生效: 默认0,表示一开始就直接用 非对齐的检查点 // 如果大于0,一开始用 对齐的检查点(barrier对齐),对齐的时间超过这个参数,自动切换成 非对齐检查点(barrier非对齐) checkpointConfig.setAlignedCheckpointTimeout(Duration.ofMinutes(4)); 5)检查点常用配置 // 1、启用检查点: 默认是barrier对齐的,周期为5s, 精准一次 env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE); CheckpointConfig checkpointConfig = env.getCheckpointConfig(); // 2、指定检查点的存储位置 checkpointConfig.setCheckpointStorage("hdfs:///ip:port/dir"); // 3、checkpoint的超时时间: 默认10分钟 checkpointConfig.setCheckpointTimeout(60000); // 4、同时运行中的checkpoint的最大数量 checkpointConfig.
Spring Boot 的各个版本通常都会支持多个 Java JDK 版本。一般来说,你可以在 Spring Boot 官方文档中找到每个版本所支持的 JDK 版本。然而,需要注意的是,商用 JDK 版本通常需要购买许可证,而开源 JDK 则是免费的。以下是一些常见的 Spring Boot 版本与 JDK 的对应关系:
Spring Boot 2.5.x: 支持 JDK 8、11、17Spring Boot 2.4.x: 支持 JDK 8、11、15Spring Boot 2.3.x: 支持 JDK 8、11、14Spring Boot 2.2.x: 支持 JDK 8、11、13Spring Boot 2.1.x: 支持 JDK 8、11Spring Boot 2.0.x: 支持 JDK 8、9、10 商用版本的 JDK 包括 Oracle JDK、IBM JDK、Azul Zulu Enterprise 等。这些商用 JDK 通常包含了一些额外的功能和支持,适用于企业级应用。