文章目录 一、while 循环1、while 循环概念2、while 循环语法结构 二、while 循环 - 代码示例1、打印数字2、计算 1 - 10 之和 一、while 循环 1、while 循环概念 在 JavaScript 中 , while 循环 是一种 " 循环控制语句 " , 使用该语句就可以
重复执行一段代码块 , 直到指定的 " 条件表达式 " 不再满足 ,如果 " 条件表达式 " 一开始就不满足 , 循环体 永远不会执行 ; 2、while 循环语法结构 while 循环语法结构如下 :
while (条件表达式) { // 循环体 代码块 } 首先 , 执行 " 条件表达式 " , 在上述语法结构中 , " 条件表达式 " 是一个 布尔类型的表达式 , 该表达式的计算结果 只能是 true 或 false ;
摘要:
随着互联网技术的快速发展,高校信息化建设已成为提升教育质量和管理效率的重要手段。学生选课管理系统作为高校信息化建设的重要组成部分,对于实现学生选课流程的自动化、规范化和智能化具有重要意义。本文基于Java Web技术,设计并实现了一个学生选课管理系统,旨在提高选课效率,优化学生选课体验,并为高校教学管理提供决策支持。
关键词:Java Web;学生选课管理系统;系统设计;系统实现
一、引言
学生选课是高等教育中的重要环节,它直接关系到学生的学习计划和高校的教学安排。传统的选课方式往往存在信息不透明、流程繁琐等问题,给学生和教师带来了不便。因此,开发一款基于Web的学生选课管理系统,实现选课流程的自动化和规范化,提高选课效率,成为高校信息化建设的迫切需求。
二、系统设计
系统架构 基于Java Web的学生选课管理系统采用B/S架构,即浏览器/服务器模式。用户通过浏览器访问系统,服务器负责处理用户的请求并返回结果。系统采用MVC设计模式,将业务逻辑、数据访问和界面显示分离,提高了系统的可维护性和可扩展性。
功能模块 系统主要包括用户管理、课程管理、选课管理、成绩管理等功能模块。用户管理模块负责用户的注册、登录、权限管理等功能;课程管理模块负责课程的添加、修改、删除和查询等功能;选课管理模块是学生和教师进行选课操作的核心模块,包括选课申请、选课审核、选课结果查询等功能;成绩管理模块负责成绩的录入、修改和查询等功能。
数据库设计 系统采用MySQL数据库进行数据存储。数据库设计包括用户表、课程表、选课表、成绩表等,通过合理的字段设计和索引优化,提高了数据的查询效率和系统的性能。
三、系统实现
前端实现 前端采用HTML、CSS和JavaScript进行页面设计和交互实现。通过Ajax技术实现页面的异步加载和数据的实时更新,提高了用户体验。同时,前端还采用了Bootstrap框架进行页面布局和样式设计,使得页面更加美观和易于使用。
后端实现 后端采用Java语言进行业务逻辑处理和数据访问。通过使用Spring框架和MyBatis框架,实现了业务逻辑与数据访问的分离,降低了代码的耦合度,提高了开发效率。同时,后端还采用了Spring Security框架进行用户认证和权限管理,保障了系统的安全性。
接口实现 系统提供了RESTful风格的API接口,供前端或其他系统进行数据交互。通过HTTP协议进行数据传输,实现了前后端的解耦和数据的共享。
四、系统测试与优化
在系统开发完成后,进行了详细的测试工作,包括功能测试、性能测试和安全测试等。通过测试,发现并修复了系统中的一些问题,提高了系统的稳定性和可靠性。同时,根据测试结果对系统进行了优化,提高了系统的响应速度和用户体验。
下面是系统运行起来后的部分截图:
五、结论与展望
基于Java Web的学生选课管理系统通过自动化和规范化的方式,提高了选课效率,优化了学生选课体验。系统的设计和实现充分考虑了用户的需求和高校的实际情况,具有较高的实用性和可扩展性。然而,系统仍存在一些不足之处,如界面的美观度、系统的智能化程度等有待进一步提升。未来,我们将继续完善系统的功能,优化用户体验,探索更多的应用场景,为高校信息化建设做出更大的贡献。
(注:上述内容仅为一个大致的框架和概述,实际撰写论文时还需要根据具体的研究内容、方法、实验数据等进行详细展开和深入分析,以满足论文的字数要求和学术标准。)
💞💞 前言 hello hello~ ,这里是大耳朵土土垚~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹
💥个人主页:大耳朵土土垚的博客
💥 所属专栏:数据结构学习笔记 、排序算法合集
💥对于数据结构顺序表、链表、堆有疑问的都可以在上面数据结构的专栏进行学习哦~ 有问题可以写在评论区或者私信我哦~
前面我们学习过四种排序——直接插入排序、希尔排序、直接选择排序和堆排序,今天我们就来学习交换排序的一种——冒泡排序。
1.什么是冒泡排序? 冒泡排序(BubbleSort)是一种计算机科学领域的较简单的排序算法。它的基本思想是通过重复遍历待排序的数据集,并依次比较相邻的两个数据项,如果它们的顺序错误则进行交换。这个过程会持续重复直到所有相邻的数据项都已经交换完毕,此时说明该数据集已经排好序。冒泡排序的名称来源于排序过程中,较小的数据项会被逐渐“浮”到数组顶部,这个过程就像碳酸饮料中二氧化碳气泡最终会上浮到顶部的现象一样。因此,这种排序算法因其这一特性而得名。
冒泡函数的核心思想就是:两两相邻的元素进行比较,一轮下来最大的或者最小的就会被交换到最后面,每一轮都得到该轮的最值排到后面,如果是升序就得到最大值,降序就是最小值,排n轮直到有序。
如下动图演示:
2.冒泡排序代码实现(升序) 2.1基础版(升序) void bubble_sort(int arr[], int sz)//参数接收数组元素个数 { for(int i=0; i<sz-1; i++)//排sz-1趟 { for(int j=0; j<sz-i-1; j++)//一趟排序 { if(arr[j] > arr[j+1])//前面的大就交换到后面,直到最后得到升序 { //交换 int tmp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = tmp; } } } } //打印数据 int main() { int arr[] = {3,1,7,5,8,9,0,2,4,6}; int sz = sizeof(arr)/sizeof(arr[0]); bubble_sort(arr, sz); for(int i=0; i<sz; i++) { printf("
🎉欢迎大家观看AUGENSTERN_dc的文章(o゜▽゜)o☆✨✨
🎉感谢各位读者在百忙之中抽出时间来垂阅我的文章,我会尽我所能向的大家分享我的知识和经验📖
🎉希望我们在一篇篇的文章中能够共同进步!!!
🌈个人主页:AUGENSTERN_dc
🔥个人专栏:C语言 | Java | 数据结构 | 算法 | MySQL
⭐个人格言:
一重山有一重山的错落,我有我的平仄
一笔锋有一笔锋的着墨,我有我的舍得
1. 数据库介绍: 数据库是按照数据结构来组织、存储和管理数据的仓库,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合.
数据库可以存储大量结构化和非结构化的数据,包括文本、数字、图像、音频等各种类型的数据。它们是计算机系统中最重要的组件之一,被广泛用于各种应用程序和业务领域。数据库管理系统(DBMS)是一种软件,用于创建、查询、更新和管理数据库中的数据,如MySQL是一种流行的DBMS。数据库设计用于有效地存储、组织和检索数据,是信息管理的核心工具,广泛应用于各种领域
1.1 为什么要使用数据库: 明明我们储存数据用文件就好了,为什么还要设计数据库这么一个软件呢?
这里我们就不得不谈到文件保存数据的几个缺点:
< 1 > 文件的安全性问题
< 2 > 文件不利于数据查询和管理
< 3 > 文件不利于存储海量数据
< 4 > 文件在程序中控制不方便
数据库存储介质:
< 1 > 磁盘
< 2 > 内存
为了解决上述的问题,专家们设计出了更加利于管理数的软件----数据库. 数据库是一个 " 客户端 -- 服务器 " 结构的程序
客户端(client) : 主动发起请求的一方
服务器(server) : 被动接受请求的一方
请求(request) : 客户端主动给服务器发的数据
相应(response) : 服务器给客户端返回的数据
DB-GPT是什么?引自官网:
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。
目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用。
总而言之:基于大模型的数据集大成者的应用。
官网文档地址
功能 私域问答&数据处理&RAG(Retrieval-Augmented Generation)
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索多数据源&GBI(Generative Business Intelligence)
支持自然语言与Excel、数据库、数仓等多种数据源交互,并支持分析报告。多模型管理
海量模型支持,包括开源、API代理等几十种大语言模型。如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱、星火等。自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。Data-Driven Multi-Agents&Plugins
支持自定义插件执行任务,原生支持Auto-GPT插件模型,Agents协议采用Agent Protocol标准隐私安全
通过私有化大模型、代理脱敏等多种技术保障数据的隐私安全 其他介绍详见官方文档 安装部署 参考源码部署
注:如本地部署大模型,可离线下载后放置DB-GPT/models目录下。
考虑大家资源有限,此处介绍代理模式安装。
代理模式即各大大模型厂商提供的API接口,有免费的、限免的、付费的,大家酌情选择。
免费/限免的有:
阿里系: https://dashscope.console.aliyun.com/billing科大讯飞:星火大模型,官网领取额度
结论:通义千问qwen-turbo模型效果稍好点。
有条件的可以上chat-gpt和智谱AI,效果更好。 参数配置 以通义千问为例。
拷贝.env.template为.env设置 LLM_MODEL=tongyi_proxyllm # PROXYLLM_BACKEND = qwen-1.8b-chat (可选模型, 免费) PROXYLLM_BACKEND = qwen-turbo EMBEDDING_MODEL=text2vec #通义千问 PROXY_SERVER_URL=https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation # Aliyun tongyi TONGYI_PROXY_API_KEY=={自己申请的key} 启动 python ./dbgpt/app/dbgpt_server.py 启动成功:
INFO: Uvicorn running on http://0.
原文《企业数字化转型之数据中台架构、大数据支撑平台、资源库建设方案》
总体架构 数据中台的总体架构以全域大数据建设为中心,覆盖整个大数据获取、治理、建立目录、共享、服务、可视化的全链路环节。
架构总体上是一种服务化的架构,各服务模块间弱耦合。每个模块对外的服务是开放性的,这意味着各种不同的模块可以按需使用。不仅如此,合理、恰当、符合逻辑的问题拆解,将每个子问题域控制在合适的粒度大小,这利于展开落地方案的架构设计,并为系统的运行演化奠定了模块化、组件化的指导基础。
各层次间的衔接与交互采取“服务化”的设计思路,层次间弱耦合,在层间通信契约稳定的前提下,各层均可独立的进行扩展变更。同时,基于这种松耦合的逻辑设计与实现,在部署架构上,可以支持灵活地按需部署,各种不同的模块部件,可以按需地分布在相同或者不同的进程单元中,并且各层次内也可以根据数据处理规模来横向伸缩扩展。
2.2、总体设计原则 数据中台的涉及内容众多,技术复杂,使用对象覆盖面广。因此,在建设时,项目规划设计应遵循以下基本原则:
先进性原则。本项目整个平台应采用先进的技术,符合技术发展趋势。数据中台采用先进技术,针对不同的业务场景,采用不同的计算和存储技术来对应等。平台采用先进的架构,各个部分之间采用松耦合,一个子系统出现问题不会影响其他系统。
易用性原则。平台应注重易用性,方便用户使用。数据中台的各个子系统注重易用性的设计,界面和操作直观、美观、方便, 易理解性,使用户抓住重点,一目了然;易操作性,提供便捷、一致的操作方式,减少用户输入和点击次数;易管理性,缩减安装、配置、实施、备份的时间和难度。
安全性原则。应充分保证数据的安全性,提供合理的解决方案。针对数据安全性,采用立体化的安全防范手段,一方面加强对现有安全设备的利用,另一方面应采用安全加密和脱敏系统加强对数据的防护,并结合已有的安全管理制度,共同形成高安全性防护。
扩展性原则。平台应考虑技术的发展和未来的应用需求,提供良好的扩展性,确保随着业务的发展能够快速进行系统的扩展。为保证系统的可扩展性设计,在系统架构上,采用系统分层设计实现。保证在设计开发上具有适应业务变化的能力,当系统新增业务功能或现有业务功能改变时(界面的改变、业务实体变化、业务流程变化、规则的改变、代码改变等),应尽可能的保证业务变化造成的影响局部化。
整体性原则。要考虑各系统之间的集成,形成一个整体对外提供服务。由于数据中台类项目涉及的子平台和子系统众多,为体现系统的整体性,应提供统一门户,完成各子平台和子系统的身份统一和集成,完成各系统的界面、应用和数据集成,确保各部分形成一个整体统一对外提供服务。
2.3、总体建设方案 中台技术建设逐步成为构建“大中台、轻应用”的信息化建设格局,加快信息化应用创新和发展,进一步解决现有数据平台瓶颈的重要手段和支撑。数据中台是中台技术的关键内容,数据中台建设主要包括数据存储、数据集成、数据治理、数据服务等方面以及相关的数据实施。数据存储、数据集成、数据治理方面主要是为了加强数据中台的数据处理能力,数据服务则主要是为了支持应用和业务的进一步创新和发展。同时,数据实施服务是数据中台建设能较好落地的基础和保障。
2.4、详细建设方案 2.4.1、数据资源梳理 本次项目需要的梳理的数据资源包括对接市局的数据资源、分局自身拥有的数据资源、调研梳理其他局委办数据资源,市局和分局的数据资源相对比较明确,其他局委办数据相对较模糊需花费一定的时间进行调研。
2.4.1.1数据资源梳理方式 在梳理信息资源时可以通过以下4种方式进行:
l、采取不同的收集手段。
A.兼容各个电子系统,收集整理数据。近几年,随着信息化建设的推动和发展,各个部门的信息化建设都有不同程度的提高。各个部门或多或少都建立起计算机系统,只是各个部门发展程度不一样,有些部门电子化程度很高,绝大多数数据都纳入到计算机系统中,而有些部门电子化的东西还很少。充分利用现有的各个电子系统,是获得信息资源最有效的途径。但在利用同时还存在一些问题,如各个部门即有自己的办公自动化系统,又有业务系统;既有以前开发的系统,又有新开发的系统;既有可公开的系统,又有密级的系统,几个系统间并不兼容,这样就需要在收集整理这些数据前,先对这些系统进行整合,抽取出符合要求的信息资源。
B.手工整理资源。各个部门信息化建设时总会有些数据资源被落下,特别是些老数据,像很多年前的档案数据、历史数据,这些数据就需要手工进行整理。
2、以信息资源的时间为主线收集。
信息资源虽然内容多而杂,但也是有规律地产生的,可以根据信息资源的产生的时间先后进行整理。时间的不同,部门所赋予的职责也会有变化,不同时期部门的名称都会有明显变化,职能的调整就更多,职能对应的资源信息也就有变化。通过时间整理数据,逻辑上比较清楚。
3、以信息资源的研究内容为主线。
以信息资源的研究内容整理数据,其实就是根据其职能范围来整理数据。根据部门的每个职能,收集相应职能所涉及到的信息资源。由于有些信息资源包含的内容比较多,因此这种整理方式会有重复收集的现象。
4、从业务应用出发进行梳理。
业务部门在履行职能、办理业务和事项中随时都需要和产生的信息资源,它的存在和分布是跨行业、跨部门、跨地域的,并且大部分信息资源随着业务的开展不断产生和变化,是一种与政府活动相关的动态信息资源。由于各个地区经济发展不同、各个部门职能不同,所拥有的政府信息资源也各不相同。
信息资源与业务密切相关的特点要求信息资源整合方法应适应业务和信息的动态产生和变化。信息资源目录体系就是从业务应用出发,梳理业务办理的流程、职责、依据等,编制信息资源目录。如针对案件研判业务,需要通过调查和梳理相关的业务环节和部门,根据业务流程,梳理和分析业务相关的信息,并且根据相关的信息资源描述规范和分类规范描述以及标识信息资源,编制面向业务的信息资源分类目录和共享目录,在目录体系的基础上进行信息资源整合。这样的整合方法为信息资源的动态有机整合建立了基础,可以适应政府信息随业务处理而动态变化的特点。
2.4.1.2信息资产梳理与编目工具 为实现对信息资产的梳理与编目,我们在信息资源管理与服务平台中提供了信息资产登记与管理系统。通过系统实现:
采用标准化工具完成基础信息资源的梳理,资源梳理工具的管理内容包括系统目标、组织结构、业务角色、用户视图等;
对业务流程图和数据流程图进行管理,能够识别协同关系和信息共享需求,能够明确职责、整理和挖掘数据资源、规范数据表示;
对数据库的主题库、逻辑实体、实体关系图、数据映射图、数据元标准、信息分类编码进行管理;通过梳理明确信息资源的出口、入口、数据间关系;
支持信息资源的文档的自动化生成(数据库设计文档、信息资源目录、实体关系图等);
支持思维导图等方式的可视化展示。
信息资源梳理的成果为数据交换提供数据来源、业务流程、资源目录、标准规范等服务支撑。
资源梳理工具的功能包括高阶导图、思维导图、业务架构、数据架构、应用架构、需求管理、文档附件、系统编码、权限管理、项目管理、系统设置等。
信息资源梳理平台通过两类视角进行说明:管理视角、维护视角。
在管理视角下进行系统编码字典、用户及权限管理、项目模块管理、系统设置等系统管理级别操作。
在维护视角下对高阶导图、业务架构、数据架构、应用架构、需求管理等功能模块内容进行编辑和查询操作。
信息资产登记
信息资产登记系统实现了各类信息资产的注册与维护,实现信息资源的编目功能。信息资产登记系统包括业务架构登记管理、数据架构登记管理和应用架构登记管理、架构资产目录管理功能。信息资产是政府架构里的核心构成和基础,对信息资产的梳理和编目、信息资产登记系统是政府整个信息化工作的灵魂和基石,信息资产登记系统产品用来支持信息资产初始化,并作为有序存储和可持续管控的起点。
在信息化工作过程中,将产生大量、复杂的信息,它们数量多、门类广、分布分散、信息资源提供者和信息资源使用者的信息不对称,这些信息只有经过梳理、分类、编目和可视化,才能变得更有价值,从而形成真正的资产,完全依靠手工和纸面管理几乎变成不可能,必须引入资产知识储藏库,通过合理的架构管控,保持定义与理解的一致性,并贯穿信息化建设的始终,对信息从产生、处理、传输、利用的全生命周期进行梳理、规划、设计和实施落地,保证信息和知识记存与使用的无歧义和连续性。为此,必须使用科学、合理、动态、活化的技术文档来存储相关信息,建立此储藏库是一个积累发展过程,首次规划资料的存储,有利于后续开发工作的进行;修订业务架构,优化数据架构和系统架构,都建立在原有知识库的基础上。
信息资产登记系统将满足其他组织建立信息资产编目体系而开发的产品,可以辅助这些组织的架构管理机构或信息部门,对业务、数据、应用等进行可视化的信息资产构建工作,并支持彼此之间的关联和可持续改进,形成清晰完整的高阶资产模型。有效支撑信息资产和企业架构开发理论、方法的具体实施。产品的信息资产知识库,存储整个开发过程中的各种资产和资源,管理层、决策层可从不同角度、视点去审视企业的结构和运作,帮助政府或企业有效实现IT战略。
该工具软件主要基于企业架构、信息工程、总体数据规划、数据管理等理论,引入高阶的架构开发方法和信息化建设中的标准化核心内容,工具通过中心数据库共享功能将各模块有机联系在一起,集中记录和管理需求,支持多团队协作和各实施阶段成果之间的一致性,同时,支持主流建模标准文档的导出。
2.信息资产管理
信息资产管理是系统维护人员对登记后的信息资产,实现有效的管理,并通过平台实现对外的可视化展现与信息资源的发布。资产管理包括资源目录的管理、文件的管理和服务的管理。
信息资产管理子系统为可视化管理平台。通过该平台,中心管理员可管理整个域内的信息资产情况,部门管理员可管理该相关部门的资产情况。信息资产管理子系统主要包括以下几大部分功能:
1、资产总体视图
2、组织机构视角
3、服务对象视角
4、信息资产视角
5、协同主题视角
2.4.2、建立数据标准和规范 建立的一套符合自身实际,涵盖定义、操作、应用多层次数据的标准化体系。
数据治理对标准的需求可以划分为两类,即基础性标准和应用性标准。前者主要用于在不同系统间,形成信息的一致理解和统一的坐标参照系统,是信息汇集、交换以及应用的基础,包括数据分类与编码、数据字典、数字地图标准;后者是为平台功能发挥所涉及的各个环节,提供一定的标准规范,以保证信息的高效汇集和交换,包括元数据标准、数据交换技术规范、数据传输协议、数据质量标准等。
2.4.2.1信息资源标准和管理规范制定 标准规范体系是虎丘区公安分局大数据中心标准化工作的核心,也是虎丘区公安局大数据中心总体设计的重要内容。虎丘区公安局大数据中心标准规范体系建设过程将按标准规范办事,使工程建设效果符合最新的行业技术质量标准规范,保证工程的先进性和可靠性,符合国家、省、市电子政务项目建设规范的要求。
2.4.2.2标准规范体系和管理规范制定思路 建立标准规范体系是实现城市大数据中心对外提供数据服务的重要支撑,是直接导致本项目建设成败的重中之重。具体的建设思路如下:
1)符合国家和虎丘公安局信息化规划的相关政策法规
项目相关标准规范体系设计及制度的制定,必须在国家和虎丘公安局相关政策的指导下,根据《中华人民共和国标准化法》,从项目建设的实际需要出发,统筹考虑大数据中心切实利益,进行制定。
2)遵循国家相关标准规范和管理规章
审查项目相关标准、规范及制度的制定,必须遵循国家信息化建设的相关标准规范,以及标准制定相关规章制度,进行起草、送审和发布。
3)从虎丘区公安局信息化建设发展的大局出发
项目相关标准、规范及制度的制定,要符合无锡市信息化建设总体思路,进行深入研究、探讨、制定,按需建立信息资源的统一数据标准。
4)充分满足本项目建设和发展要求
说明 参数估计在科研、工程乃至生活中都有广泛的应用。参数估计要解决的问题简单来说就是:基于一组观测数据,通过某种方法来获得我们想要的,与观测数据相关的一个或多个参数。
克拉美-罗界(Cramr-Rao Bound, CRB)是无偏估计里我们常用的且十分重要的一种对不同参数估计方法性能评价的参考(对比)指标:对于同一组观测数据,可能会有很多不同的方法来做估计 并得到各自的估计结果,那么,这些方法的优劣(包括其相对优劣、以及参数估计结果与真实值的逼近程度)如何,需要我们提出一种客观的评价指标(参考),克拉美罗界就是这样一个指标。
当然,克拉美罗界的用处不止于此,以及关于什么是无偏估计,我将在本博文中做出更详细的说明。 克拉美罗界是参数估计相关paper中不可或缺的元素,在去年一个老哥带我发的一篇文章中,审稿人之一对我们提了这样的要求:“The CRLB should be also include to show the performance benchmark for the estimation algorithms.”那会儿对CRLB还没有什么概念…,初看了一下觉得蛮繁琐,匆匆写了个理由忽悠过去了(可能主要是期刊比较水所以能忽悠过去…),后面就一直拖到现在才得空来对这个概念做一些学习和梳理,并形成了本篇博文。
关于CRLB,网上确实有一些比较好的资料,但是读者若要系统以及细节地理解参数估计以及关于CRLB的概念,建议看看参考资料[1]。本文的内容相对简单,主要是试图理清楚关于参数估计、无偏估计、CRLB的由来和原理等概念,并以一维线阵为例,给出线阵DOA估计的CRLB、不同DOA估计算法的性能比较。可能会有一些错误,欢迎读者评论指正,我会不定期补充维护。
Blog 2024.3.25 博文第一次撰写
目录 说明
目录
一、参数估计&克拉美罗下界基本概念
二、线阵&单目标下 不同DOA估计算法方差结果及其与CRLB对比
2.1 不同SNR下的结果
2.2 不同角度下的结果
2.3 小结
三、总结
四、参考资料
五、代码
一、参数估计&克拉美罗下界基本概念 参数估计要解决的问题简单来说就是:基于一组观测数据,通过某种方法来获得我们想要的与观测数据相关的一个或多个参数。现在计算机技术、AD转换等技术已经发展得足够成熟了,在雷达、声呐、通信等各类系统中,我们一般都会将各类模拟量采样并存储为离散时间波形,因此,参数估计问题就是从得到的离散时间波形或数据集中提取参数的问题。用数学语言来表达就是:假设我们有N点的数据集合:{x[0],x[1],x[2],…x[N-1]},它与未知参数y有关,我们希望基于该数据集合来确定估计量y:
(1-1)
式中,g是某个函数(某种参数估计方法)。是参数y在g方法下的估测值。对应到本博文后面将要探讨的一维线阵的DOA估计问题:这里的x就可以理解成每个接收通道采集的数据,y是目标角度,我们做DOA估计的方法有很多(关于DOA估计,读者可以参考我之前写过的一篇博文[2]:车载毫米波雷达DOA估计综述-CSDN博客)。比如有经典的FFT、DBF、Music、Capon等。
这便是参数估计问题。
而无偏估计是指估计量的平均值为未知参数的真值。对应到前面的数学语言上,即假设我们有M组N点的数据集合:第一组为 X_1:{x_1[0],x_1[1],x_1[2],…x_1[N-1]}、第二组为X_2: {x_1[0],x_1[1],x_1[2],…x_1[N-1]}、以此类推一直到第M组。我们用方法g对这M组的数据进行估计,可以得到M个,此时,如果:
(1-2)
式中y为参数的真值,则我们称该估计为无偏估计。我们基于FFT、DBF、Music、Capon的方法做线阵的DOA估计都属于无偏估计。
如前文说明中所述,对于同一组观测数据,可能会有很多不同的方法来做估计并得到各自的估计结果,那么此时我们会感兴趣的一个问题是:大多数情况下,哪一种估计方法得到的估计量是更优的? 一个很自然的想法是:均方误差(mean square error, MSE),其定义为:
(1-3)
均方误差度量了估计量偏离真值的平方偏差的统计平均值,对于同一个参数,如果某种估测方法下得到估测值的均方误差越小,我们可以认为其更优!但遗憾的是,该准则的采用导致我们无法得到最优估计量,因为这个估计量不能写成数据的唯一函数,我们可以将上式重写: (1-4)
进一步地:
(1-5)
上式表明,MSE是由估计量的方差 (方差是针对估计量的均值,而均方差是针对真值)以及偏差引起的误差组成的。这里面包含了参数真值,我们无法求得使MSE最小的参数估计值。
但是,如果我们将问题约束(限定)为无偏估计问题呢?由前文对无偏估计的讨论我们知道,无偏估计下,此时跳开了真值,最小MSE(也就对应了最小方差)对应的估计量是可以实现的!这样的估计量被称为最小方差无偏(minimum variance unbiased, MVU)估计量。
此时新产生的一个问题是:对于任意一个参数无偏估计问题,我们使用不同的参数估计方法得到的参数估计值的最小方差能小到多少? 这个最小的方差值,就是所谓的克拉美罗下界(Cramer-Rao Lower Bound, CRLB)。如果某种参数估计方法下得到的参数估计值,其方差值等于克拉美罗下界,我们认为该估计方法是最优的(至少是最小方差无偏估计)。
📝个人主页:五敷有你 🔥系列专栏:中间件
⛺️稳中求进,晒太阳
1.数据卷(容器数据管理) 修改nginx的html页面时,需要进入nginx内部。并且因为内部没有编辑器,修改文件也很麻烦。
这就是因为容器与数据(容器内文件)耦合带来的后果。要解决这个问题,必须将数据与容器解耦,这就要用到数据卷了。
1.1.什么是数据卷 数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录。
一旦完成数据卷挂载,对容器的一切操作都会作用在数据卷对应的宿主机目录了。
这样,我们操作宿主机的/var/lib/docker/volumes/html目录,就等于操作容器内的/usr/share/nginx/html目录了
1.2.数据集操作命令 数据卷操作的基本语法如下:
docker volume [COMMAND] docker volume命令是数据卷操作,根据命令后跟随的command来确定下一步的操作:
create 创建一个volume
inspect 显示一个或多个volume的信息
ls 列出所有的volume
prune 删除未使用的volume
rm 删除一个或多个指定的volume
1.3.创建和查看数据卷 需求:创建一个数据卷,并查看数据卷在宿主机的目录位置
① 创建数据卷
docker volume create html ② 查看所有数据
docker volume ls 结果:
③ 查看数据卷详细信息卷
docker volume inspect html 结果:
可以看到,我们创建的html这个数据卷关联的宿主机目录为/var/lib/docker/volumes/html/_data目录。
小结:
数据卷的作用:
将容器与数据分离,解耦合,方便操作容器内数据,保证数据安全
数据卷操作:
docker volume create:创建数据卷
docker volume ls:查看所有数据卷
docker volume inspect:查看数据卷详细信息,包括关联的宿主机目录位置
docker volume rm:删除指定数据卷
docker volume prune:删除所有未使用的数据卷
1.4.挂载数据卷 我们在创建容器时,可以通过 -v 参数来挂载一个数据卷到某个容器内目录,命令格式如下:
VSCode编写JavaScript ■ 下载安装VSCode■ VSCode统一配置■ 格式化工具■ Tab size (代码缩进 2个字符)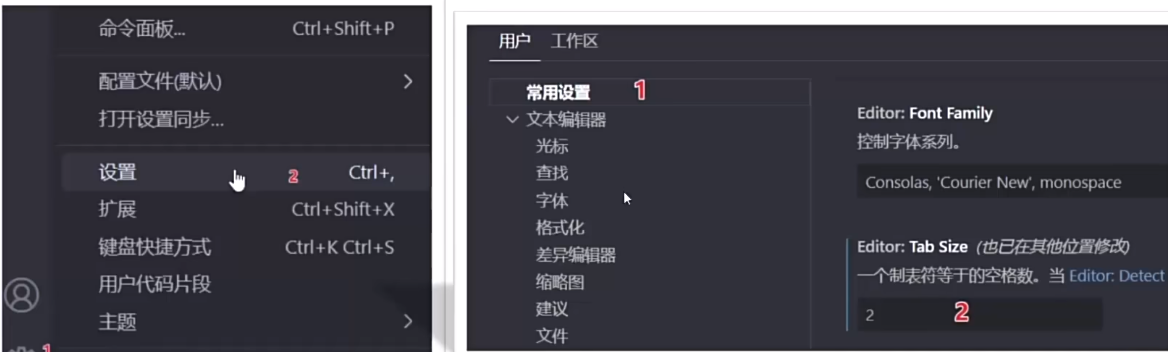 ■ VSCode安装JS插件■ VSCode新建JS工程代码■ 方法一:使用VSCODE插件Code Runner运行JS代码■ 方法二■ 方法三 ■ VSCode调试JS代码** ■ 下载安装VSCode 从微软官方链接 可以打开Visual Studio Code主页
由于目前是在Windows系统,故选择Windows 10, 11并点击对应x64的User Installar下载安装包。
■ VSCode统一配置 ■ 格式化工具 //注意: 不要安装格式化插件;可以使用vscode自带的格式化工具就行了,如下:
■ Tab size (代码缩进 2个字符) ■ VSCode安装JS插件 插件描述验证过Error Lens代码编写报错PassOne Dark Pro颜色主题,安装完成后还要点击设置颜色主题按钮。PassLive Server左右分屏,可以模拟浏览器演示Javascript运行结果。 win + 左右箭头PassJavaScript(ES6)代码片段:提供ES6的代码片段和语法高亮。JavaScript(Standard)代码片段:提供JavaScript Standard Style的代码片段。ESLint:提供代码风格的检查和修复。Prettier:提供代码格式化功能。IntelliSense显示智能代码完成(即代码补全)、悬停信息和签名信息,以便你可以更快、更正确地编写代码。Babel JavaScript代码提供语法高亮显示 ■ VSCode新建JS工程代码 ■ 方法一:使用VSCODE插件Code Runner运行JS代码 安装插件Code Runner
新建demo.js文件
console.log(“666”)Run Code 运行代码
安装了 Code Runer之后,重启VSCODE,选中要运行的JS文件右键选择 Run Code 运行代码,就可以在控制台查看运行结果了。
一、背景介绍
当使用ChatGPT时,模型的回复不是一次性生成整个回答的,而是逐字逐句地生成。这是因为语言模型需要在每个时间步骤预测下一个最合适的单词或字符。如果等待整个回复生成后再输出到网页,会导致用户长时间等待,极大降低用户体验。
相反,逐字蹦出回复可以实现更快的交互响应。ChatGPT可以在输入消息后迅速开始生成回答的开头,并根据上下文逐渐细化回答。这种渐进式的呈现方式可以提供更流畅的对话体验,同时让用户知道模型正在工作,避免感觉像卡住了或没有响应。此外,逐字蹦出的回复还有助于用户跟踪模型的思考过程,看到它逐步构建回答的方式。这种可见的生成过程有助于用户理解模型是如何形成回答的,提高对话的透明度和可解释性。
那么,ChatGPT是用什么技术来实现流式输出的呢?
二、ChatGPT流式输出原理
我们看一下ChatGPT的completion API的官方文档
其中有一个stream参数,其介绍如下:
可以看到,当stream设置为true时,将会使用SSE(Server-Sent Events)技术流式输出结果。我们curl调用一下。
结果如下:
可以看到,响应头的类型是content-type: text/event-stream,表示这个响应是文本流输出,然后响应体每次都以data:开头,后面携带的是一个json数据,最后以data: [DONE]作为结束标志。
ChatGPT流式输出的耗时比非流式输出耗时长,如果不需要打字机效果,建议使用非流式
三、SSE技术介绍
SSE (Server-Sent Events) 技术是一种用于实现服务器主动推送数据给客户端的通信协议。相比传统的请求-响应模式,SSE提供了一种持久连接,允许服务器随时向客户端发送事件和数据,实现了实时性的消息传递。
SSE的工作原理非常简单直观。客户端通过与服务器建立一条持久化的HTTP 连接,然后服务器使用该连接将数据以事件流(event stream)的形式发送给客户端。这些事件流由多个事件(event)组成,每个事件包含一个标识符、类型和数据字段。客户端通过监听事件流来获取最新的数据,并在接收到事件后进行处理。
与WebSocket 技术相比,SSE使用的是基于 HTTP的长轮询机制,而不需要建立全双工的网络连接。这使得SSE 更容易在现有的基础设施上部署,无需特殊的代理或中间件支持。另外,SSE能够与现有的 Web技术(如 AJAX 和RESTful API)很好地集成,同时也更适合传输较少频繁更新的数据。
SSE 的优点包括:
实时性:SSE 允许服务器主动将数据推送给客户端,实现实时更新和通知。
简单易用:SSE 基于标准的 HTTP 协议,无需额外的库或协议转换。
可靠性:SSE 使用 HTTP 连接,兼容性好,并能通过处理连接断开和错误情况来确保数据传输的可靠性。
轻量级:与 WebSocket 相比,SSE 不需要建立全双工连接,减少了通信的开销和服务器负载。
然而,SSE也有一些限制。由于 SSE基于 HTTP长轮询机制,每个请求都需要建立和维护一个持久化连接,这可能导致较高的资源消耗。此外,SSE适用于单向通信,即服务器向客户端发送数据,而客户端无法向服务器发送消息。
综上所述,SSE技术提供了一种简单、实时的服务器推送数据给客户端的方法,适用于需要实现实时更新和通知的应用场景。它在Web 开发中具有广泛的应用,可用于构建聊天应用、实时监控系统等,并为开发人员带来便利和灵活性。
四、SSE前端实践
在本章中,我们将探讨如何使用JavaScript的EventSource来实现流式输出。EventSource是一种支持服务器发送事件(Server-Sent Events)的API,它提供了一种简单而有效的方式来接收服务器端的实时数据。
首先,我们需要在前端创建一个EventSource对象,并指定要连接的服务器端URL。下面是一个示例代码:
上述代码中,我们通过指定'/stream'作为EventSource的URL来连接到服务器端的SSE端点。当服务器端有新数据发送时,onmessage回调函数将被触发,我们可以在这里处理接收到的数据。常见的处理方式包括更新页面内容、添加新元素或执行其他操作。
另外,onerror回调函数用于处理连接错误的情况。当连接关闭时,我们可以相应地处理,例如显示错误信息或尝试重新连接。对于其他类型的错误,我们可以在控制台打印错误消息以便调试。
在流式输出中,如何判断数据流何时结束是一个重要问题。在SSE中,当服务器端关闭连接时会触发onerror回调函数,我们可以在这里处理连接关闭的情况。此外,我们还可以在服务器端发送特定的标识来表示数据流的结束,然后在前端进行相应的处理。
如果在连接过程中出现网络问题或其他错误,onerror回调函数也会被触发。在这种情况下,我们可以根据具体的错误处理机制来决定如何处理,例如重新连接或显示错误信息。
通过使用EventSource库,我们可以轻松地在前端实现与服务器端的流式通信。无论是实时聊天、实时数据更新还是其他需要实时性的应用场景,SSE都提供了一种简单且可靠的解决方案。在实践中,我们可以根据具体的需求和业务逻辑,灵活地使用SSE来实现各种流式输出的功能。
使用EventSource需要注意以下问题:
1.结束标识 服务器端应发送特定的标识来表示数据流的结束,然后前端调用close关闭EventSource。如果不这么做的话,当服务端发送完数据关闭连接后,EventSource默认会自动重新连接。
2.只支持GET url可以携带一些简单的查询参数,如果要传输复杂的请求体,可以考虑两次请求的方案。先通过普通的HTTP POST/PUT请求,将请求体传送到服务端。服务端将请求体缓存起来,并返回一个能唯一标识的票据,前端最后使用EventSource在url中带上票据,服务端根据票据从缓存里取出请求体。
3.不支持自定义Header 接口如果需要鉴权,无法在Header里定义Authorization请求头,那么建议使用Cookie来标识用户,EventSource请求会携带Cookie。
LEO:LogEndOffset 当前日志文件中下一条待写信息的offset
HW/LEO这两个都是指最后一条的下一条的位置而不是指最后一条的位置。
LSO:Last Stable Offset 对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同
LW:Low Watermark 低水位, 代表 AR 集合中最小的 logStartOffset 值
4. Kafka中是怎么体现消息顺序性的?
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。
整个topic不保证有序。如果为了保证topic整个有序,那么将partition调整为1.
5. Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
拦截器->序列化器->分区器
6. Kafka生产者客户端的整体结构是什么样子的?
7. Kafka生产者客户端中使用了几个线程来处理?分别是什么?
2个,主线程和Sender线程。主线程负责创建消息,然后通过分区器、序列化器、拦截器作用之后缓存到累加器RecordAccumulator中。Sender线程负责将RecordAccumulator中消息发送到kafka中.
9. Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
10. “消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?
不正确,通过自定义分区分配策略,可以将一个consumer指定消费所有partition。
11. 消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
offset+1
12. 有哪些情形会造成重复消费?
消费者消费后没有commit offset(程序崩溃/强行kill/消费耗时/自动提交偏移情况下unscrible)
13. 那些情景下会造成消息漏消费?
消费者没有处理完消息 提交offset(自动提交偏移 未处理情况下程序异常结束)
14. KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
1.在每个线程中新建一个KafkaConsumer
2.单线程创建KafkaConsumer,多个处理线程处理消息(难点在于是否要考虑消息顺序性,offset的提交方式)
15. 简述消费者与消费组之间的关系
消费者从属与消费组,消费偏移以消费组为单位。每个消费组可以独立消费主题的所有数据,同一消费组内消费者共同消费主题数据,每个分区只能被同一消费组内一个消费者消费。
16. 当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
创建:在zk上/brokers/topics/下节点 kafkabroker会监听节点变化创建主题
删除:调用脚本删除topic会在zk上将topic设置待删除标志,kafka后台有定时的线程会扫描所有需要删除的topic进行删除
17. topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以
18. topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不可以
19. 创建topic时如何选择合适的分区数?
根据集群的机器数量和需要的吞吐量来决定适合的分区数
20. Kafka目前有那些内部topic,它们都有什么特征?各自的作用又是什么?
🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 【AI】大模型API调研及推荐引入调研KimiAPI对接 国内GPT4的转发API对接 总结 【AI】大模型API调研及推荐 引入 最近写了脚本对接用阿里云的通义大模型API来完成一些社区的问题回答,以此获得一些每日的积分和流量。🤤
为什么选择阿里云的通义大模型呢?因为在此之前是免费的,然而,最近开始收费了。是的,价格还是蛮贵的,看了下我之前调用的模型是qwen-max,都收费到了0.12元/1000 tokens。这个收费是什么概念呢,我统计了下,我每天用这个API回答5个问题, 我最近20天回答了100个问题,就用了大概 1000 * 1000 tokens,还好在免费额度里,算了下账,都差点要120元了😭.
大家都知道程序员的💰是最难赚的,是的,所以我果断就选择了弃用阿里云的API,开始调研大模型最便宜的方案。
PS: 有小伙伴们会问,有一些模型才0.008元/1000 tokens呀。是的,但是调用大模型最好就调用最好的,这样可以省去很多时间。🐶
调研 于是楼主在相关论坛上发布了相关帖子进行调研。其中有两个方案呼声最高。分别如下:
月之暗面的Kimi国内的GPT4转发站 国内的GPT4转发站请自寻寻找,由于这种转发站具有不稳定性(这里的不稳定是指我不知道会不会搭建房圈钱跑路亦或是提高价格杀熟🐶) 所以此处不贴链接,还请谅解。
Kimi 呼声最高的便是当今国内人工智能炸子鸡公司,月之暗面,这家公司融资了10亿美元,旗下的Kimi可以说是国内长文本最🐮的利器。价格在0.024元/1000 tokens,而且注册用户还送15元,爽歪歪。
这里分享两个常用链接:
直接可以对话使用的KimiKimi的研发文档 API对接 由于我这里使用的都是http请求对接,我这里就贴下http请求的js代码, 本人自用,欢迎自取。😃
const callMoonShot = async (prompt) => { const url = "https://api.moonshot.cn/v1/chat/completions"; const params = { model: "moonshot-v1-32k", messages: [ { role: "user", content: prompt, }, ], }; const res = axios .
首先,点击该链接进去下载首页 https://mvnrepository.com/
可以搜自己想要的包,以Jackson为例
点击进去,往下滑就可以选择自己要下载的版本,可以根据自己的需求选择版本号,我以2.13.4为例
该页面有两个东西,一个是下载jar包,一个是maven导入Jackson包。
(1)下载jar包
进入下载页面,选择jar包就可以下载了
(2)maven导入Jackson包
看到下面的界面
往下滑,选择maven,就可以拷贝该语句了
本文为学习笔记,所参考文章均已附上链接,若有疑问请私信!
创作不易,如果对你有点帮助的话麻烦点个赞支持一下!
新手小白,欢迎留言指正!
文章目录 前言一、下载并安装Tesseract OCR二、配置环境变量三、Python中安装使用pytesseract总结 前言 Tesseract OCR是一个开源OCR(Optical Character Recognition)引擎,用于从图像中提取文本。Pytesseract是Tesseract OCR的Python封装,它使得在Python中使用Tesseract OCR引擎变得容易。Pytesseract提供了简单的API,帮助开发者轻松地使用Tesseract OCR引擎来实现图像中文本的识别。本文主要介绍了Windows下安装Tesseract OCR、并在Python中使用pytesseract进行本地文字识别的流程。
一、下载并安装Tesseract OCR 在Tesseract OCR下载地址https://digi.bib.uni-mannheim.de/tesseract/下载合适的版本安装包,如下:
点击安装包进行安装:
语言选择英文:
如果需要识别中文,则可以在安装过程中勾选下载中文语言包和脚本(也可以按需选择繁体):
自定义安装路径:
然后一直选择默认选项进行安装即可。
二、配置环境变量 为了方便使用Tesseract,需要将软件安装目录添加到系统环境变量中,这样不必每次执行命令时都切换到Tesseract的安装路径,如下:
设置确定后之后,可以进行验证,打开CMD,输入tesseract --version,示意如下:
C:\Users\LENOVO>tesseract --version tesseract v5.3.0.20221214 leptonica-1.78.0 libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0 Found AVX2 Found AVX Found FMA Found SSE4.1 Found libarchive 3.5.0 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 libzstd/1.4.5 Found libcurl/7.
随着人工智能技术的不断发展,我们的日常工作和学习方式正在经历一场革命。在众多创新工具中,GPT(Generative Pre-trained Transformer)已经成为了一个耀眼的明星, 而这个月Claude3的登场,再次将人工智能推向新一轮高峰。
为什么要使用AI? 提高效率 GPT、Claude等,作为先进的自然语言处理模型,能够帮助我们快速生成文章、编写代码、解答问题等。这意味着,不论是写作业、工作报告还是编程,都能助你一臂之力,大幅提升工作效率。
创意启发 当你面临写作障碍或思维僵化时,这些工具能够提供多样化的想法和表达方式,激发你的创造力,让你的作品更具创意和吸引力。
学习与研究 这些AI不仅是写作工具,还是一个强大的学习伴侣。它能够提供各领域的信息,帮助你进行研究,甚至辅助你学习新的语言。
考虑到访问速度、便利性、使用频率等问题,我目前还是镜像站用得多,附上自用的各镜像站,均无需魔法,大家需要的自取。
sora(sora展示站,无法实时生成,只是收集了一些sora生成的视频进行展示,如果对AI生成视频感兴趣又无法去官网看的话,可以上这个网站看看)
free2gpt(GPT3.5,免费,无需登录,限制120次/天)
gpt4(GPT4.0镜像站,付费,需邮箱登录)
claude(Claude 3 Opus镜像站,付费,需邮箱登录,据说测评比GPT4还要强,不过费用好像也比GPT贵)
chat web(GPTweb导航站,有列出可用、不可用,或需关注公众号等等)
提示词(提示词网站,不知道怎么用,怎么问的时候,可以上去找找灵感)
希望各大公司继续卷,卷出新高度,卷出更大的性价比,而让普通用户可以在它们之间,依据自己的需求选用适合的模型,在智能水平、处理速度和成本之间,找到最佳平衡。
要启用通用构建,在最新版本的 Xcode 中,请打开您的项目设置,然后依次选择:
1.
“Build Settings” 选项卡。
2.
在顶部输入框中输入 “Architectures”。
3.
在 “Architectures” 下拉列表中选择 “Other”。
4.
在输入框中输入 “arm64 x86_64”,然后单击 “+” 来添加这个架构组合。
5.
选择 “Build Active Architecture Only” 选项并将其设置为 “No”。
6.
在搜索框中输入 “Mach-O Type”。
7.
在 “Mach-O Type” 下拉列表中选择 “Dynamic Library” 或者 “Executable”。
8.然后在Xcode选择Any Mac
9.run project,用Product–>Build For–>Running,不要用左边的运行按钮
目录
一、点击进入Redis官网
二、点击RedisInsight
三、接着点击 here链接
编辑 四、点击下载
五、注册一下信息
编辑 六、安装成功后测试连接
一、点击进入Redis官网 https://redis.io/download/
二、点击RedisInsight 三、接着点击 here链接 四、点击下载 五、注册一下信息 六、安装成功后测试连接
1. 基本原理 1.1 requests 模块 requests 是 Python 中一个非常流行的 HTTP 客户端库,用于发送所有的 HTTP 请求类型。它基于 urllib,但比 urllib 更易用。
中文文档地址:Requests: 让 HTTP 服务人类 — Requests 2.18.1 文档
(1)requests.get(url, **kwargs) requests.get() 函数是 requests 库中用于发送 HTTP GET 请求的主要函数。GET 请求通常用于从服务器请求数据,而不发送任何数据到服务器(尽管可以通过查询参数发送少量数据)。下面我将介绍 requests.get 函数的参数、用法,并给出一个简短的例子。
参数: url (str): 请求的 URL。这是 requests.get 必须的参数,想要请求的网页或资源的地址。
params (dict, optional): 一个字典或字节序列,作为查询参数增加到 url 中。例如,params={'key1': 'value1', 'key2': 'value2'} 将会以 key1=value1&key2=value2 的形式附加到 URL 上。
headers (dict, optional): 自定义 HTTP 头。例如,可以通过 headers={'User-Agent': 'my-app/0.0.1'} 来设置用户代理。
cookies (dict, optional): 字典或 CookieJar,包含要发送的 cookie。
目录
一.最长公共子序列的基本概念:
解决动态规划问题的一般思路(三大步骤):
二.最长公共子序列题目:
三.字符串的删除操作:
四.最小 ASCII 删除和:
一.最长公共子序列的基本概念: 首先需要科普一下,最长公共子序列(longest common sequence)和最长公共子串(longest common substring)不是一回事儿。什么是子序列呢?即一个给定的序列的子序列,就是将给定序列中零个或多个元素去掉之后得到的结果。什么是子串呢?给定串中任意个连续的字符组成的子序列称为该串的子串。给一个图再解释一下:
最长公共子序列,顾名思义,就是求两个字符串中子序列的最长的公共部分,返回这个最大的长度,比如说输入 s1 = "zabcde", s2 = "acez",它俩的最长公共子序列是 lcs = "ace",长度为 3,所以算法返回 3。
🐻🐻🐻对于两个字符串求子序列的问题,都是用两个指针 i 和 j 分别在两个字符串上移动,大概率是动态规划思路。
解决动态规划问题的一般思路(三大步骤): 动态规划,无非就是利用历史记录,来避免我们的重复计算。而这些历史记录,我们得需要一些变量来保存,一般是用一维数组或者二维数组来保存。下面我们先来讲下做动态规划题很重要的三个步骤:
🧐 步骤一:定义dp数组元素的含义🧐步骤二:找出数组元素之间的关系式(也就是我们所熟知的状态转移方程)🧐第三步骤:找出初始值(base case) 接下来的题目我们会按照这三个步骤来解释说明
二.最长公共子序列题目: 计算最长公共子序列(Longest Common Subsequence,简称 LCS)是一道经典的动态规划题目,力扣第 1143 题「最长公共子序列open in new window」就是这个问题:
对应的函数签名如下:
步骤一:按我上面的步骤说的,首先我们来定义 dp数组的含义,题目要我们求两个字符串的最长公共子序列,给出 对应dp[][] 数组的定义:dp[i][j] 表示串 s1[0..i] 和 s2[0..j] 最长公共子序列的长度步骤二:找到数组元素之间的关系式(也就是我们所熟知的状态转移方程) 这里咱不要看 s1 和 s2 两个字符串,而是要具体到每一个字符,思考每个字符该做什么:
①.如果我们只看 s1[i] 和 s2[j],如果 s1[i] == s2[j],说明这个字符一定在 lcs 中: 根据dp数组定义可得此时状态转移方程为:dp[ i ][ j ] = 1 + dp[ i - 1 ][ j - 1 ]
前言 jdk是Java开发必要的编程环境,idea是常用的Java开发工具,这里着重解释一下maven。
maven就是我们经常看见的pom.xml文件,maven有以下三点功能:
1.项目构建(可以帮助我们更快速的打包、构建项目)
2.依赖管理,例如我们连接数据库需要的jar包驱动、处理excel表格的驱动等,还有相应的war包、xml文件等。maven可以帮助我们统一管理。
3.统一开发结构:如下图
maven功能架构图:
一、jdk下载安装 1.jdk22下载链接:https://www.oracle.com/cn/java/technologies/downloads/#jdk22-windows
2.双击安装
3.点击下一步
4.选择合适的java安装路径,注意路径不能有中文字符
5.至此,点击关闭,安装结束
二、jdk环境变量配置 1…找到刚才安装Java的目录,并复制下来
2.搜索栏搜索编辑系统环境变量并打开
3.点击环境变量
4.在用户变量中点击“新建”
5.变量名字为JAVA_HOME,变量值就是刚才复制的java所在的目录,建完点击确定
6.如图所示,新建成功
7.双击用户目录的“Path”,然后点击“新建”,输入%JAVA_HOME%\bin,我们只能用到这个bin文件夹
8.三个“确定”!!!一定不要忘记
9.打开cmd,输入java -version,验证java环境是否配置成功
如图所示,显示出Java的版本,证明配置成功
三、maven下载安装 1.下载链接:https://maven.apache.org/download.cgi
2.点击下载
3.下载完毕后,选择一个目录将其解压,注意路径不能有中文。
四、maven仓库配置 1.在maven解压完毕的文件夹中创建jar文件夹,用于存放我们以后项目开发下载的jar包。同时复制该文件夹路径。
2.找到maven的conf文件夹,然后双击打开,然后找到settings.xml文件,然后右击打开方式,用记事本或者编译软件打开都行。(我这里使用vscode打开的)
3.编辑settings文件:
第一步配置本地仓库:
在被注释掉的<localRepository> </localRepository>标签下面添加一个<localRepository>d:\maven\apache-maven-3.9.6\jar</localRepository>(标签里面的路径就是刚才复制的jar文件夹的路径)
第二步配置远程仓库:
(我们这里使用的是国内的阿里云镜像)
找到<mirrors></mirrors>标签,将原本的镜像注释掉(或者直接删掉),然后写入新的镜像:
<mirror> <id>aliyunmaven</id> <mirrorOf>*</mirrorOf> <name>阿里云公共仓库</name> <url>https://maven.aliyun.com/repository/public</url> </mirror> 修改完毕,如图所示:
保存后退出,我们的maven的本地仓库和远程仓库均已经配置完毕。
五、idea的maven环境配置 1.打开idea,点击新建项目
2.选择maven项目,并给项目命名,我这里命名为test,然后选择项目存储位置,我这里选择的是D:\idea2023\project,然后点击create
3.进入项目后,点击file,点击settings
4.依次找到如图所示的目录
5.依次配置以下两个路径,第一个路径是我们电脑上将maven解压的位置路径,第二个是maven的settings文件路径(选择好第一个文件路径,第二个路径点击Override一般会自动生成)
6.点击Apply,再点击OK,我们的maven就配置成功了!