根据官网介绍,Node.js 是一个免费的、开源的、跨平台的JavaScript实时运行环境,允许开发人员在浏览器之外编写命令行工具和服务器端脚本.
Node.js框架由于是采用JavaScript语法进行调用的,因此Node.js环境除了用来编写调试Node.js代码,也可以用来编写调试原生的JavaScript代码。
Step.01:Node.js环境安装 1.在Node.js官网下载msi文件: 下载地址: Node.js — Download
假定安装路径在: D:\Program Files\nodejs\
Node.js安装包自带npm工具。
2.检查Node.js是否安装成功: 打印node.js版本号: node -v
打印npm版本号:npm -v
3.Node.js环境变量配置: 修改npm包和node.js缓存的存储路径:
npm config set cache "D:\Program Files\nodejs\node_cache" npm config set prefix "D:\Program Files\nodejs\node_packages" 把镜像源改为国内: npm config set registry http://registry.npm.taobao.org 查看当前镜像源: npm config get registry 查看npm当前安装的依赖包:
npm list 安装一个npm包试试: Step.02:在VSCode上简易配置Node.js开发环境 打开一个JavaScript脚本文件Demo.js,然后打开VSCode界面上的"运行和调试"界面选择"Node.js"。
Step.03:去官网找一个Node.js的demo代码运行 官网地址: Node.js简介
Demo: 利用node.js搭建一个简单的服务
const http = require('http'); const hostname = '127.0.0.1'; const port = 3000; const server = http.
Python的安装和配置 一、下载Python安装包 首先,你需要从Python的官方网站(https://www.python.org/downloads/)下载适合你操作系统的Python安装包。请注意,Python 2.x版本即将停止维护,因此推荐下载Python 3.x版本。
二、安装Python 下载完成后,双击打开安装包进行安装。仔细阅读安装向导,选择适合你的安装选项。对于大多数用户来说,选择默认的安装选项即可。选择安装路径。建议选择一个简洁且没有空格和特殊字符的路径,以避免后续可能出现的问题。在安装过程中,请确保勾选“Add Python to PATH”选项。这将把Python解释器添加到系统环境变量中,使得你可以在任何位置通过命令行调用Python。 三、验证安装是否成功 安装完成后,你可以通过以下步骤验证Python是否安装成功:
打开命令提示符(Windows用户)或终端(Mac/Linux用户)。输入python --version并回车。如果安装成功,你将看到显示的Python版本号。
四、配置IDE(可选) 虽然Python自带了IDLE这个简单的IDE,但对于复杂的开发任务,你可能需要一个更强大的IDE,如PyCharm、VS Code等。这些IDE提供了丰富的功能,如代码高亮、自动补全、调试工具等,可以大大提高开发效率。
配置IDE的步骤通常包括:
下载并安装IDE。在IDE中配置Python解释器的路径。这通常可以在IDE的设置或首选项中找到。你需要指向你之前安装的Python解释器的位置。 五、安装pip(Python包管理工具) pip是Python的包管理工具,它允许你安装和管理额外的Python库和工具。在大多数情况下,pip会随Python一起自动安装。你可以通过以下命令验证pip是否已安装:
pip --version 如果pip没有自动安装,你可能需要手动安装它。具体的安装步骤可以在Python的官方文档中找到。
六、使用pip安装Python包 一旦你安装了pip,你就可以使用它来安装各种Python包。例如,如果你想安装一个名为requests的库,你可以在命令行中输入以下命令:
pip install requests pip会自动从Python包索引(PyPI)中下载并安装这个库。
通过以上步骤,你应该已经成功地在你的计算机上安装和配置了Python环境。现在你可以开始编写和运行Python代码了!
PIP 国内镜像配置 pip设置国内镜像可以大大提高下载Python包的速度,因为默认的源位于国外,可能会导致下载速度较慢或连接不稳定。以下是如何设置pip国内镜像的步骤:
1. 选择国内镜像源 国内有多个pip镜像源可供选择,例如阿里云、中国科技大学、中国科学院和清华大学等。你可以根据个人喜好和网络情况选择一个镜像源。以下是几个常用的镜像源地址:
阿里云:https://mirrors.aliyun.com/pypi/simple/中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/中国科学院:https://pypi.mirrors.opencas.cn/simple/清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 2. 临时使用镜像源安装Python包 如果你只是想在单次安装时使用镜像源,可以在安装命令中添加-i参数指定镜像源地址。例如,使用阿里云的镜像源安装requests包:
pip install requests -i https://mirrors.aliyun.com/pypi/simple/ 3. 永久配置pip使用镜像源 如果你想让pip永久使用某个镜像源,你需要修改pip的配置文件。以下是在Windows和Linux/Mac系统上设置永久镜像源的方法:
Windows系统: 进入用户目录,例如C:\Users\你的用户名。在该目录下新建一个名为pip的文件夹(如果还没有的话)。在pip文件夹中创建一个名为pip.ini的文件(如果还没有的话)。使用文本编辑器打开pip.ini文件,并添加以下内容(以阿里云为例): [global] index-url = https://mirrors.aliyun.com/pypi/simple/ 保存并关闭文件。现在,pip应该默认使用你指定的镜像源了。
Linux/Mac系统: 在你的家目录下创建或编辑一个名为.pip/pip.conf的文件(如果还没有的话)。你可以使用文本编辑器(如nano或vim)来创建或编辑这个文件。在文件中添加以下内容(以阿里云为例): [global] index-url = https://mirrors.aliyun.com/pypi/simple/ 保存并关闭文件。现在,pip应该默认使用你指定的镜像源了。
注意事项 如果你在配置过程中遇到权限问题,可能需要以管理员或root权限来创建或编辑配置文件。注意,最新的pip版本都要求安全链接,因此必须是https协议有时候,你可能需要清除pip的缓存,以确保它使用新的镜像源。可以使用pip cache purge命令来清除缓存。如果在设置镜像源后仍然遇到问题,可以尝试换一个镜像源或者检查你的网络连接。 通过以上步骤,你应该能够成功配置pip使用国内镜像源,速度飞起哦:
IDLE集成环境的使用 有了Python够吗?还不够,开发老司机都知道,要高效,还得有个集成开发环境IDE。Python自带一个IDE环境IDLE,但是呢功能就比较简单了,用来学习尚可,用来生产那就差强人意,使用IDLE进行Python编程的基本步骤如下:
这个问题是Android Studio和SDK升级后出现的,在打包apk时会出现报错。 首先找到build.gradle文件
在targetSdkVersion上面加一行注释:
//noinspection ExpiredTargetSdkVersion 然后在Android{}块中加入 lintOptions { abortOnError false } 以下为完整代码图
再次打包就ok了
下面是一些常见的希腊字符及其对应的快捷键:
α (Alpha): Option + Aβ (Beta): Option + Bγ (Gamma): Option + Gδ (Delta): Option + Dε (Epsilon): Option + Eζ (Zeta): Option + Zη (Eta): Option + Hθ (Theta): Option + Qι (Iota): Option + Iκ (Kappa): Option + Kλ (Lambda): Option + Lμ (Mu): Option + Mν (Nu): Option + Vξ (Xi): Option + Xο (Omicron): Option + Oπ (Pi): Option + Pρ (Rho): Option + Rσ (Sigma): Option + Sτ (Tau): Option + Tυ (Upsilon): Option + Uφ (Phi): Option + Fχ (Chi): Option + Cψ (Psi): Option + Yω (Omega): Option + W 按住"
文章目录 概要整体流程图片预览技术细节小结 概要 什么是AI绘图:
简单来说,AI作画就是利用人工智能技术进行绘画创作的过程。 在这个过程中,AI会根据用户的需求和喜好,自动生成相应的绘画作品。 例如,用户可以要求AI生成一幅具有某种风格和主题的绘画作品,AI就会根据用户的要求生成相应的绘画内容。
AI 绘画的价值: AI 绘画技术的优势在于能够快速生成高质量的图像。相比传统的手工绘画,AI 绘画更加高效和精准。同时,AI 绘画也能够创造出更加新颖和独特的艺术风格,为艺术创作带来了更多的可能性。
在艺术创作方面,AI 绘画已经开始成为一种新的艺术形式。许多艺术家和设计师开始利用 AI 绘画技术进行创作,创造出具有独特风格的作品。此外,AI 绘画技术还可以应用于游戏开发和影视制作中。游戏开发者可以利用 AI 技术生成游戏场景和角色模型,大大提高游戏开发的效率。影视制作方面,AI 技术可以用来生成特效和虚拟场景,使得电影和电视剧的制作更加真实和精彩。
市面上主流的AI绘图工具:
1、Midjourney是由Leap Motion開發的AI繪圖工具,相對其他常見的AI繪圖網站, Midjourney相對快速且精準逼真的繪圖技術,成功令不少用家感到讚歎。Midjourney的界面操作相對難學習,而且由於Midjourney是利用社交平台Discord來創作的,因此容易被其他平台使用者的作品訊息而滋擾。早於3月底Midjourney停止了免費試用的功能,因此現時如果只可以以月費或年費訂閱服務,售價為10至60美元不等(折合約78至470港元)
工具地址:https://www.midjourney.com/home/
入门教程:http://www.sucaijishi.com/articles
2、DALL·E 2是由ChatGPT的母公司OpenAI所開發。OpenAI早於2010年發布上一代版本DALL·E後,翌年便推出優化版的DALL·E 2,使其圖像生成及繪製的結果更加準確和逼真。同時圖像輸出的解像度亦提高了4倍。除了基本AI繪圖創作外,用家還可以使用修復工具來移除圖像中的指定元素,添加陰影、紋理和反射等效果。DALL·E2的新用家可以有15個免費積分的試用限額,用光後便要付費使用了。
官网:https://openai.com/dall-e-2/
绘画网址:https://labs.openai.com/
是否需要科学上网:需要,IP地址最好是美国,不然容易被屏蔽。
目前是否收费:收费。
界面比较简洁,输入文字描述,就能快速生成一张AI创作的艺术画作;它还能根据你提供的原画作,拓展延伸画出画布外面的画面;还可以对原画作进行编辑,如在画面中添加/删除一个元素,同时兼顾阴影、反射、材质等;以原画作为灵感创造出新的作品。
3、Stableboost是一個專門根據用家上載的人像、寵物和產品等圖像,重新繪畫出具指定風格的AI繪圖工具。同一張照片,Stableboost可以一次過同時為你創作出100種風格以供選擇,同時每張畫作的解像度更高達2K。除了可以用圖像作為指令外,Stableboost亦有部分修圖功能及將解像度較低的照片放大等。Stableboost的收費以一組照片計算,一組照片的基本收費是12.99美金(即約101港元),為100張照片分別提供100種不同的風格。額外圖像要求需另外收費。
//Stable-Diffusion(SD)是开源且免费的软件,因此,理论上我们可以自己按照官方安装教程来进行安装。但是!非常非常麻烦,很容易出错报错,不建议.
4、DreamStudio,大名鼎鼎的stable-diffusion的官方团队除了提供了一个免费开源的软件之外,也搭建了一个在线平台,主要是 dreamstudio.ai。大家可以免费试玩。
官网:https://stability.ai/
测试版地址:https://beta.dreamstudio.ai/home
是否需要科学上网:不需要。
目前是否收费:不收费,但试用次数有限(可多次注册不同账户)
5、NovelAI是一個訂閱式的AI服務網站,其中提供圖像生成及輔助式故事寫作功能。即係可以根據用家的寫作風格、能力及背景而成為用家的影子作家。其後再進一步推出圖像生成服務。NovelAI提供試用版本,其後用家便需要以訂閱制來享用服務,收費由10至25元美金不等。(即約78至196港元)。
6、Stable Diffusion是一個以用家的文字輸入指令﹐從而產生圖像的免費AI繪圖模型。它的生成速度快,加上圖片可以用作商業用途,大大提高圖像的可用性。但據部分用家分享,Stable Diffusion在逼真度上仍然不及Midjourney,例如經常沒法準確地描繪出眼睛和手指等人體細微處,令人像作品有時看起來怪怪的。
7、必应(bing)图像创建,必应官方有一个图像创建网站,基本完全免费,免安装,就是需要自己注册一个微软账号。由于微软账号注册相对简单,我们这里就不专门展开了。
官网:https://www.bing.com/
可以看到左上角有一个图片的按钮,可以点进去,进入后右上角有一个图像创建者,点击进入即可
绘画网址:https://www.bing.com/create
这里提醒的一点是,必须使用Microsoft Edge,对!就是那个你曾经看不起的IE!
改头换面之后,他现在可牛逼了!
反正我觉得现在非常好用!
微软投资OpenAI的决定真的是牛逼!
不过,目前国内还没使用,必须科学上网,位置设置为美国。
然后顺便说一句,必应首页的图片旁边就是聊天功能,其实就是接入了ChatGpt,不过目前体验效果一般,经常出错,不如直接使用ChatGpt友好。
最后说一句,必应用的图像创建功能也是由OpenAI旗下的DALL·E提供的。
8、文心一格是由百度公司推出的人工智能艺术和创意辅助平台。输入文字描述,即可生成不同风格的创意画作。
官网:https://yige.baidu.com/
是否需要科学上网:不需要。
目前是否收费:收费,不过可以试用。
Midjourney流程举例: 接下来我拿我现在用的Midjourney注册使用的流程举例,让大家更直观的去了解:
1、第一步:架梯子,这个就不细讲了,自己去买也行,借用也行
2、先注册一个Discord账号https://discord.gg/:这个注册也简单,就人机校验然后正常安装流程点击注册就行了。
注:Discord 一款专为社群设计的免费通讯社交软体,类似于LINE或Slack。在Discord直接搜索Midjourney即可使用。类似于Midjourney类似于微信里面的小程序,只不过功能着实强大
有LeetCode算法/华为OD考试扣扣交流群可加 948025485
可上全网独家的 欧弟OJ系统 练习华子OD、大厂真题
绿色聊天软件戳 od1336了解算法冲刺训练
文章目录 题目描述与示例题目描述输入描述输出描述补充说明示例输入输出补充说明 解题思路代码解法一:DFSpythonjavacpp时空复杂度 解法二:BFSpythonjavacpp时空复杂度 华为OD算法/大厂面试高频题算法练习冲刺训练 题目描述与示例 题目描述 为了达到新冠疫情精准防控的需要,为了避免全员核酸检测带来的浪费,需要精准圈定可能被感染的人群。现在根据传染病流调以及大数据分析,得到了每个人之间在时间、空间上是否存在轨迹的交叉。现在给定一组确诊人员编号 (X1, X2, X3, ..., n),在所有人当中,找出哪些人需要进行核酸检测,输出需要进行核酸检测的人数。(注意:确诊病例自身不需要再做核酸检测)
需要进行核酸检测的人,是病毒传播链条上的所有人员,即有可能通过确诊病例所能传播到的所有人。
例如:A是确诊病例,A和B有接触、B和C有接触、C和D有接触、D和E有接触,那么B\C\D\E都是需要进行核酸检测的人。
输入描述 第一行为总人数N
第二行为确诊病例人员编号(确诊病例人员数量<N),用逗号分割
第三行开始,为一个N*N的矩阵,表示每个人员之间是否有接触,0表示没有接触,1表示有接触。
输出描述 整数:需要做核酸检测的人数
补充说明 人员编号从0开始
0 < N < 100 示例 输入 5 1,2 1,1,0,1,0 1,1,0,0,0 0,0,1,0,1 1,0,0,1,0 0,0,1,0,1 输出 3 补充说明 编号为1、2号的人员,为确诊病例。
1号和0号有接触,0号和3号有接触。
2号和4号有接触。
所以,需要做核酸检测的人是0号、3号、4号,总计3人需要进行核酸检测
解题思路 本题让人回想那段岁月…恍若隔世
非常典型的搜索问题,很容易想到直接套用DFS/BFS模板来完成。
注意所给的无向图是以关联矩阵mat来呈现的,即mat[i][j] == 1表示i和j有关联(有接触)。
另外,需要注意进行搜索的初始节点可能有多个。若
进行DFS,那么需要多次进行DFS入口函数的调用进行BFS,那么队列的初始状态需要储存多个节点 注意:本题存在一个非常坑的地方,就是原本已经确诊的人是无需再做核酸检测的,只有连通块中的其他人才需要做检测。
如果不熟悉关联矩阵,也可以将关联矩阵转化为邻接表来表示。
复习一下无向图关联矩阵的特点:
mat[i][j] == 1表示i和j关联,mat[i][j] == 0表示i和j无关对角线一定为1,即mat[i][i] == 1恒成立,因为每一个人总和自己关联关联矩阵一定沿着对角线对称,即mat[i][j] == mat[j][i],因为i和j关联等价于j和i关联 代码 解法一:DFS python # 题目:2023C-精准核酸检测 # 分值:100 # 作者:闭着眼睛学数理化 # 算法:DFS # 代码看不懂的地方,请直接在群上提问 def dfs(n, i, checkList, mat): global ans ans += 1 # 将编号i标记为已检查过 checkList[i] = 1 # 遍历所有与i关联的编号j for j in range(n): # 1.
文章目录 前言一、HDFS的UI页面介绍1. 概述页面2. 数据节点页面2.1 单个数据节点信息页面 3. 数据卷故障信息页面4. 快照信息页面5. 启动进度信息页面6. 文件系统页面 二、YARN的UI页面介绍1. 应用程序页面2. 集群相关信息页面3. 集群节点信息页面4. 应用程序调度信息页面5. 工具栏信息页面 总结 前言 本文将介绍Hadoop分布式文件系统(HDFS)和YARN的用户界面(UI)页面。通过这些UI页面,用户可以方便地查看集群的状态、节点信息、应用程序运行情况等,提高管理和监控效率。了解和使用HDFS和YARN的UI页面对于有效地管理和利用Hadoop集群至关重要。
一、HDFS的UI页面介绍 1. 概述页面 概述页面包括hadoop集群的概述信息、HDFS内存使用总结信息、NameNode 日志状态信息、NameNode 存储信息、NameNode 存储类型信息。
2. 数据节点页面 数据节点页面可以查看数据节点的信息和状态。
点击单个节点的http地址可进入单个节点信息页面。
2.1 单个数据节点信息页面 可以查看单个节点的相关信息,包括块池信息,数据卷信息和日志信息等。通过9864端口进入。
日志信息页面可以查看单个节点的日志相关信息。通过**/logs**路径进入。
3. 数据卷故障信息页面 数据卷出现故障时,可在此处查看故障信息。
4. 快照信息页面 可查看Hadoop的快照表目录和快照目录的信息。
5. 启动进度信息页面 可查看hadoop启动的进度信息。
6. 文件系统页面 进入文件系统页面。
文件系统可以查看相关文件系统信息,包括查看保存的文件、创建目录、上传文件和下载文件等。
二、YARN的UI页面介绍 1. 应用程序页面 应用程序页面可以查看集群指标、集群节点指标、用户指标、调度指标和程序运行情况等信息。
点击红框中相关选项,可查看新建、已提交、运行中、已完成和已失败等的应用程序信息。
2. 集群相关信息页面 可查看集群的相关信息。
3. 集群节点信息页面 可查看节点的信息。
4. 应用程序调度信息页面 可查看应用程序的调度信息。
5. 工具栏信息页面 点击相关选项可以查看配置、日志和服务器指标等信息。
总结 本文介绍了HDFS和YARN的UI页面,帮助用户更好地了解和使用这些关键组件。通过HDFS的UI页面,用户可以查看集群的概述信息、数据节点状态、存储信息等,而YARN的UI页面则提供了集群指标、节点信息、应用程序调度信息等的可视化展示。通过这些UI页面,用户可以更方便地管理和监控Hadoop集群,提高工作效率。
希望本教程对您有所帮助!如有任何疑问或问题,请随时在评论区留言。感谢阅读!
✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。
🍎个人主页:海神之光
🏆代码获取方式:
海神之光Matlab王者学习之路—代码获取方式
⛳️座右铭:行百里者,半于九十。
更多Matlab仿真内容点击👇
Matlab图像处理(进阶版)
路径规划(Matlab)
神经网络预测与分类(Matlab)
优化求解(Matlab)
语音处理(Matlab)
信号处理(Matlab)
车间调度(Matlab)
⛄一、chan+taylor算法移动基站无源定位简介 1 引言
随着无人机的普及,低空空域的安全问题受到人们的极大关注.针对该问题,本研究对“非合作型”无人机采用一种基于时差法的无源定位算法对其进行实时定位.基于时差法的无源定位方法是根据求解无人机信号到达主站和各辅站的距离差,并联合各基站坐标所构成的双曲线方程组来实现.该方法定位精度高,且不对外发射信号,可在机场等区域安全使用.
目前,Chan算法和Taylor算法是2种经典的时差定位算法.其中,Chan算法在时差值精确的情况下,可以实现较高精度的定位,但如果时差值精度不够,其定位精度会大幅降低.Taylor算法则是在已有的定位坐标基础上,进行迭代递归,使定位出的坐标接近于目标的真实坐标.虽然Taylor算法定位精度较高,但需要提供初始估计坐标,否则就无法实现准确定位.基于2种算法的特点,本研究提出Chan-Taylor联合算法,其思路是,将Chan算法解算出的目标坐标作为初始估计坐标值赋给Taylor算法进行迭代运算,即使获取的时差值存在一定误差,使初始估计坐标的精度不高,但可以通过迭代来提高定位坐标的精度.通过算法对比和仿真分析表明,Chan-Taylor联合算法较Chan算法具有更高的定位精度和稳定性,较Taylor算法更具有实用性.
2 算法描述
2.1 Chan算法
基于Chan算法的无源定位是通过求解目标源信号到达辅站与主站之间的时差并联立各基站坐标所得的双曲线方程组来实现的.该算法是一种非迭代算法,不需要初始值,在时差精确、视距传输的情况下,其定位效果良好,但在工程上,很难获得满足要求的时差初值.因此,Chan算法可作为其他算法的前置条件.
本研究以4站三维定位系统为例建立3组方程,该方程组为超定方程组.通常情况下,由于该方程组导出的矩阵不存在逆矩阵,方程组无法正常求解.所以,本研究利用伪逆法联合最小二乘法对方程组进行解算,即Chan算法.4站定位系统的定位原理如图1所示.
图1 4站定位系统示意图
图1中,主站坐标联立3个辅站坐标,通过分别计算出的时差可构建3条双曲线,其交点就是无人机的位置.
假设无人机位置为P=[px,py,pz],各基站坐标为Pi=[pix,piy,piz],i∈[0,3],则无人机到基站i的距离ri2可表示为,
本研究若不特别指明,均默认i∈[1,3].对式(1)整理可得,
式中,Ri表示基站i到坐标原点的距离;R0为主站到坐标原点的距离;ri0为无人机到辅站与主站间的距离差.
4站三维定位系统存在一个由3组式(2)的关系式结合而成的方程组,如式(3)所示.当A≠0时,线性方程组(3)有解.
式中,A是方程组的系数矩阵,b是方程组的输出向量.
利用伪逆法可求得无人机坐标为,
2.2 Chan-Taylor联合算法
因为Chan算法是非递归算法,对时差精度要求高,因此,本研究对该算法的定位结果进行二次处理.Taylor算法是利用局部最小二乘解进行迭代[5]的递归算法,其定位精度高,但需要初始估计坐标,否则无法进行定位.
基于低空无人机时差定位的实际需求,本研究结合Chan算法和Taylor算法提出了一种改进的算法,即Chan-Taylor联合算法.Chan-Taylor联合算法是将Chan算法的解算结果作为初始估计坐标送入Taylor算法,以达到对无人机坐标进行误差计算和定位修正的作用.算法在迭代时,将误差与设定的阈值进行比较,若误差值大于阈值,则继续迭代;若误差值小于设定阈值,则终止迭代并输出结果.
2.3 Chan-Taylor联合算法流程及计算原理
Chan-Taylor联合算法流程如图2所示,具体为:首先,算法获得无人机信号到主站与各辅站之间的时差;然后,将时差用于Chan算法部分进行初始估计坐标值的计算,并利用该坐标值在Taylor算法部分做误差向量的计算,用以定位修正;同时,对误差进行阈值比较.如不满足条件,则继续迭代,如满足条件,则结束迭代,并输出最终结果.
图2 Chan-Taylor算法流程
式中,α为目标差值向量,b为时差的差值向量,e为时差估计误差向量,H为时差估计的梯度矩阵.它们可分别表示为,
由式ri0=ri-r0=cτi0与站址坐标,可得,
将式(10)与式(11)联立,化简可得,
⛄二、部分源代码 % 比较两种算法在6基站情况下的误差对比
%the simulation of TDOA localization algorithm
clear all;
clc;
%定义四个参与基站的坐标位置
% BS1=[0,0];BS2=[20,0];BS3=[20,20];BS4=[0,20]; BS5=[10,10]; BS6=[5,15];
% MS=[15,14]; %移动台MS的初始估计位置
% std_var=[1e-3,5e-3,1e-2,5e-2,8e-2,1e-1]; %范围 图中标出的点的个数
报错信息: Err:1 http://cn.archive.ubuntu.com/ubuntu jammy/main amd64 libtcl8.6 amd64 8.6.12+dfsg-1build1
Temporary failure resolving ‘cn.archive.ubuntu.com’
Err:2 http://cn.archive.ubuntu.com/ubuntu jammy/main amd64 tcl8.6 amd64 8.6.12+dfsg-1build1
Temporary failure resolving ‘cn.archive.ubuntu.com’
Err:3 http://cn.archive.ubuntu.com/ubuntu jammy/universe amd64 tcl-expect amd64 5.45.4-2build1
Temporary failure resolving ‘cn.archive.ubuntu.com’
Err:4 http://cn.archive.ubuntu.com/ubuntu jammy/universe amd64 expect amd64 5.45.4-2build1
Temporary failure resolving ‘cn.archive.ubuntu.com’
E: Failed to fetch http://cn.archive.ubuntu.com/ubuntu/pool/main/t/tcl8.6/libtcl8.6_8.6.12%2bdfsg-1build1_amd64.deb Temporary failure resolving ‘cn.archive.ubuntu.com’
E: Failed to fetch http://cn.archive.ubuntu.com/ubuntu/pool/main/t/tcl8.6/tcl8.6_8.6.12%2bdfsg-1build1_amd64.deb Temporary failure resolving ‘cn.archive.ubuntu.com’
E: Failed to fetch http://cn.archive.ubuntu.com/ubuntu/pool/universe/e/expect/tcl-expect_5.45.4-2build1_amd64.deb Temporary failure resolving ‘cn.
Stable Diffusion Web UI安装教程
简介 这是一款ai学习的作图模型训练,github的官网地址是https://github.com/AUTOMATIC1111/stable-diffusion-webui
参考上面的github仓库中的README.md文件可以搭建本地化服务。该搭建过程需要一些编程基础,当然,如果没有的话只要按照文档中的步骤一步步去做个人觉得问题应该也不是很大,里面针对macos以及windows系统做了bat和sh文件一键安装脚本。当然,安装前提是你的计算机本身有python环境,Git环境等。具体可参考:
https://openai.wiki/stable-diffusion-webui-localization.html
安装完成后启动本地访问地址:http://127.0.0.1:7860
模型概念 模型概念解析:
基础模型:作为基础,即按照某种基础进行模型生成人物模型:在基础模型的前提下,额外扩展个性化模型 基础模型一般都会推荐使用chilloutmix_NiPrunedFp32Fix.safetensors。
而人物模型则花样百出,例如koreanDollLikeness_v15.safetensors韩国人物模型,或者taiwanDollLikeness_v10.safetensors台湾人物模型。
针对这两种不同定义的模型,我们虽然在网站上下载的模型文件后缀都是. safetensors,但是我们放置在stable-diffusion-webui目录下的位置上不一样。
模型下载:
基础模型存放位置:models/Stable-diffusion/,即chilloutmix_NiPrunedFp32Fix.safetensors就会存放在该目录下,官方下载地址:https://civitai.com/models/6424/chilloutmix 大概是4g左右
人物模型存放位置:stable-diffusion-webui/models/Lora/,即koreanDollLikeness_v15.safetensors或者taiwanDollLikeness_v10.safetensors就会存放在该目录下,官方下载地址:https://civitai.com/ 选择lora标签就可以查到大量的人物模型。同时也可以选择第三方的人物模型下载地址:https://openai.wiki/lora.html
插件简介 插件下载:
下载ControlNet 插件教程:https://openai.wiki/controlnet-install.html
有可能存在下载失败的情况,参考以下解决方案:https://www.bilibili.com/video/BV1RD4y1A7Cb
txt2img参数设定:
korean
lora:koreanDollLikeness_v15:0.66, best quality, ultra high res, (photorealistic:1.4), 1 girl, (aegyo sal:1), Kpop idol, sitting down, spread legs, sports bra, miniskirt, black hair, (braided hair), full body, cute, smile, ((puffy eyes)), facing front, (facing viewer), see through, thin waist, huge breasts, armpits, arms up, ulzzang-6500:1 Negative prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot
🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 引入 以前看到同事们锁屏的时候,不知按了什么键,直接调出这个框,然后输入lock屏幕就锁了。
跟我习惯的按Mac开机键不大一样。个人觉得还是蛮炫酷的~
调研 但是由于之前比较繁忙,这件事其实都忘的差不多了,直到后来看帖子看到一个问题才让我继续往下调研。
问题是Raycast 相比 Alfred 好在哪。
凭借我多年的看《名侦探柯南》的经验,线索已经找到了。Raycast和Alfred,但我秉持着只用一个同类型软件的原因,于是对这两款软件进行调研。
Alfred 付费策略: 需要付费,价格35英镑,大概相当于310人民币🤑使用体验: 更像一个工具,除了最基本的内置功能外,可能需要折腾它,经过一通复杂的设置才能让它工作UI界面: 比较老,毕竟是老款的提效工具。 Raycast 付费策略:免费,爽歪歪🤩使用体验: 更像是服务,适配了不少常用的小功能,不需要复杂的设置,上手即可使用,带有插件系统。UI界面: 做的比较不错,很多人都是因为UI选择了它 你问我选择了什么,我肯定选择免费的哇, 免费的香呀🤤。
使用 下载软件 首先,我们去网站下载这个软件。链接如下: www.raycast.com/
安装完,我们打开,会发现mac顶栏有一个新的图标,点击选择open Raycast即可打开。
常用功能 启动本地应用 🌟🌟 这应该是最常用的功能了,输入要搜索的软件名字就能快速打开。
快捷链接 🌟🌟 调起Raycast,输入quick,打开Create Quicklink。我按照默认配置了一个快捷的Google Seach其中的query字段是需要查询的文本,我们默认用Query填充。
使用的时候我们在Raycast里输入Google Search然后按住Tab键,填入要搜索的Query就能查找啦。
剪贴板历史 🌟🌟🌟 存储最近Ctrl+C的历史,再也不用害怕之前Ctrl+C的丢失了。
打开Clipboard History,我这里设置了Control + Option + Space快捷键。
打开就可以看到最近的复制历史了,而且还支持图片,文本等的分类,简直不要太爽!🤤
快捷窗口布局 🌟🌟🌟 我们有些时候需要把全屏的缩小为半屏,或是半屏的放大为全屏。很多时候,我们只能用手指划到页面的左上角进行操作,非常考验手指的灵活性,以及很容易让指关节疲劳。而RayCast刚好可以设置快捷键从而快速支持。
我们打开RayCast输入window,就可以看到有这么多可以设置window的选项了,我一般给常用的4个设置快捷键,分别如下
名称快捷键Toggle Fullscreencontrol + command + upCenter Halfcontrol + command + downLeft Halfcontrol + command + leftRight Halfcontrol + command + right
打开新项目时出现一下错误:
Unsupported Java,Your build is currently configured to use Java 17.0.9 and Gradle 5.6.4.
这说明使用的java版本过高,而 gradle5.6.4对应的是java8,最新安装的编译器java版本是17
解决方法是为项目配置低版本的JDK,这里选择jdk版本为1.8的,设置好路径(注意文件夹为空和不能有空格)
最后重新编译一下项目即可
目录
一、逻辑备份
1、备份数据
1.全库备份
2.库级备份
3.表级备份
4.备份表结构
5.导出数据,不导出表结构
1.查看安全路径:
2.导出数据
3.导入数据
6.恢复数据 1.恢复数据库 2.恢复数据表
7.更改数据库导出安全目录
二、根据二进制日志文件恢复数据
1、开启binlog日志功能
2、重启数据库
3、模仿数据库数据丢失
4、查看二进制日志
5、恢复数据
第一种方法:根据position位置点
第二种方法:根据时间恢复
三、物理备份
1、全量备份
1.建立备份文件所需存放的目录
2.开始备份 3.恢复数据
2、增量备份 3、差异备份
一、逻辑备份 备份的是建表、建库、插入等操作所执行SQL语句,适用于中小型数据库,效率相对较低。
本质:导出的是SQL语句文件
优点:不论是什么存储引擎,都可以用mysqldump备成SQL语句
缺点:速度较慢,导入时可能会出现格式不兼容的突发情况,无法做增量备份和累计增量备份。
提供三种级别的备份,表级,库级和全库级
逻辑备份: 备份的是建表、建库、插入等操作所执行SQL语句(DDL DML DCL),适用于中小型数据库,效率相对较低。
数据一致,服务可用。:如何保证数据一致,在备份的时候进行锁表会自动锁表。锁住之后在备份。
本身为客户端工具: 远程备份语法: # mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql 本地备份语法: # mysqldump -u用户名 -p密码 数据库名 > 备份文件.sql 常用备份选项:
-A --all-databases \ 备份所有库
-B --databases bbs test mysql 备份多个数据库
前端需要导入表格进行数据匹配,并进行表格导出,感谢很多大佬的文章分享,有不对的地方欢迎大家指正。 Element + xlsx 安装命令 npm install xlsx 页面引入 import XLSX from 'xlsx' 一、excel表格导入到表格 <template> <div class="main"> <div class="main_title">工具</div> <div class="main_content main_bg"> <div class="table_title" > <div class="fl left_tbl"> <div> <el-upload class="fl upload-demo" action="" ref="upload" accept=".xls,.xlsx" :file-list="fileList" :on-change="handleChange" :show-file-list="false" :auto-upload="false"> <el-button type="success">导入数据</el-button> </el-upload> <div class="fl filename" >{{formName}}</div> <div class="cf"></div> </div> <div class="left_tbl_1"> <el-table :data="tableData" border style="width: 100%" class="tb-edit" height="450" @cell-click="clickCell" :row-class-name="rowClass"> <el-table-column label="序号" type="index" width="50" v-if="tableData.length>0" align="center"></el-table-column> <template v-for="(item,index) in dataName"
基于Qt和百度AI智能云实现的智能车牌识别系统,具体可实现为停车场管理系统、智能计费停车系统…等。
注:详细资料/教程/帮助请联系作者(见文末)。
1.系统实现思路及框架 1.1实现思路 要实现一个车牌识别系统,有多种方法,例如用opencv图像算法实现,或用第三方算法接口,选择一种合适的方式。除算法部分外,还需要有用户交互界面即UI,UI界面的实现也有多种方法,也需要多种方法对比选出适合的一种。
此外,还有很重要的一项,用哪种语言实现,如C/C++,python,java …等。
1.1.1系统功能需求 要做一个项目,首先要明确系统的功能有哪些,再根据功能思考该如何实现。该项目的功能有如下:
打开摄像头并能实时显示画面;车牌识别,能准确识别出摄像头拍到的车牌号码;识别到车牌后,能显示车牌号码,并截下车辆图片;若是车库或收费系统,还需要录入/删除车牌,计费等功能。 关于编译语言,多种语言均可实现,这里选择C/C++。
1.1.2界面实现 UI界面的实现,本系统选择最常用的QT库,本系统的所有UI界面都能实现,包括各种界面显示,如视频显示,文字/图像等,还有用户交互的部分,如按钮,输入框等操作控件。此外,QT库学习入门快、网上资料教程多等也是选择的原因之一。
1.1.3车牌识别实现 车牌识别,不选择算法复杂的opencv,而是选用简单调用接口的百度AI平台。用百度AI平台,具体算法方面不用关心,只需要按照其访问要求来对接即可,即发送的内容要按照百度AI定义的协议要求来组织,具体要查看百度AI官方文档,后续再具体讲解。
1.2系统框架 1.2.1硬件框架 系统的硬件主要分为两大部分:PC主机和ARM开发板,即需要一块ARM-Linux开发板(带屏幕),一个摄像头,一台PC主机,一根网线(开发板与PC主机连接)。
硬件框架
1.2.2软件框架 系统的软件框架主要分为三大部分:前台(ARM开发板)、后台(PC主机)、百度智能云。
前台(ARM开发板)主要功能是采集图像、信息显示等;后台(PC主机,ubuntu)主要是车牌管理(录入/删除车牌等)、对接百度智能云平台;百度智能云主要是识别车牌信息。
2.系统开发环境搭建 PC主机的运行环境是在windows上运行的虚拟机ubuntu系统。
2.1 Qt开发环境 界面采用QT进行开发,主要安装qt creator即可。
qt creator安装程序是图形化界面的,像在windows上安装软件一样,比较简单,不再累述。
2.2百度AI开发环境 与百度AI的通信方式是https,因此,百度AI相关的环境主要有OpenSSL库、Curl库和Json库的安装。
2.2.1 OpenSSL库安装 下载openssl库:/source/index.html (openssl.org)
实验版本:openssl-1.1.1s.tar.gz
将openssl库源码包放到ubuntu下,解压出来,并进入解压出来的目录。
配置编译选项:主要配置安装路径
$ ./config –prefix=/usr/local/openssl
编译:
$ make
安装:
$ sudo make install
安装完成,可在安装路径下见到openssl
2.2.2 Curl库安装 下载curl源码包:curl-7.88.0.tar.gz
下载地址:curl downloads
亦可用命令下载:
$ wget https://curl.se/download/curl-7.88.0.tar.gz
将源码包放入ubuntu,解压出来,并进入解压出来的目录:
配置编译选项:指定安装在/usr/local/curl目录,指定openssl的路径,
$ ./configure --prefix=/usr/local/curl --with-ssl=/usr/local/openssl
编译
$ make
目录
1.PCA基本原理
2.人脸识别应用
3.MATLAB程序
4.仿真结果
人脸识别(Face Recognition)是一种生物特征识别技术,它通过比较和分析人脸的物理特性来验证或识别个人身份。该技术基于人的面部特征信息进行模式匹配,可以应用于安全系统、社交媒体、移动设备解锁、支付验证、视频监控等多种场景。由于人脸图像通常包含大量冗余信息,直接进行识别往往效率低下且容易受噪声影响。因此,特征提取成为人脸识别中的一个关键步骤。PCA作为一种经典的降维技术,被广泛应用于人脸特征提取。
1.PCA基本原理 主成分分析(Principal Component Analysis, PCA)是一种常用的数据降维方法,常用于人脸识别中的人脸特征提取。其基本思想是通过线性变换将原始高维图像数据映射到一组新的正交基(即主成分)上,这些主成分按方差递减顺序排列,最大程度地保持了原始数据的变异信息。
PCA算法步骤:
数据预处理: 首先对收集的人脸图像数据进行标准化处理,确保每个样本的均值为0,方差为1,这可以通过如下公式实现:
计算协方差矩阵: 对于预处理后的数据集,计算其协方差矩阵 ΣΣ,表示各维度之间的统计相关性:
求解特征值与特征向量: 通过对协方差矩阵求特征值分解得到: Σ=ΛΣ=VΛVT 其中,�V 是由协方差矩阵对应的特征向量构成的矩阵,Λ 是对角线上元素为对应特征值的对角矩阵,特征值按照从大到小排列。
选择主成分: 根据累计贡献率或预定阈值选取前k个最大的特征值所对应的特征向量作为主成分。转换后的低维特征向量可通过以下公式获取:Z=XVk 其中,Vk 是包含前k个特征向量的子矩阵,Z 是经过PCA转换后的新特征向量。
人脸识别: 在训练阶段,使用PCA提取的人脸特征构建模型;在测试阶段,同样对新的人脸图像执行PCA降维,然后用降维后的特征与训练集中的人脸特征进行比对,通过距离度量方法如欧氏距离或者更复杂的分类器来实现人脸识别。
2.人脸识别应用 在人脸识别中,PCA被用于从训练集的人脸图像中提取特征。这些特征构成了所谓的“特征脸”(Eigenfaces),它们是人脸图像集合中的主要变化模式。在识别阶段,新的人脸图像会被投影到这些特征脸上,得到一组特征系数。这些系数与预先存储的特征系数进行比较,从而识别出最相似的人脸。
3.MATLAB程序 function f=PCA(U,trainallsamples,testallsamples,dim) %faces.mat为ORL人脸图像库,共40人,每人10幅图像,其中每人的前5幅作为训练样本, %后5幅作为测试分类样本,统计正确分类率。分类准则为最近邻规则。 %真实的图像尺寸为112x92=10304,列向量堆积对应人脸库矩阵的每一列。 %num=numbpatten/2; %dim=num/2;%%为样本的特征选取数 num=size(trainallsamples,2); %% 获得训练样本的特征 Y1=zeros(dim,num);%为训练样本的特征100*200 for i=1:num Y1(:,i)=U'*trainallsamples(:,i); end %% 获得测试样本特征 Y2=zeros(dim,num);%为训练样本的特征100*200 for i=1:num Y2(:,i)=U'*testallsamples(:,i); end %% % trainsamples is 训练样本,testsamples is 测试样本 %Y1=Getpatten(trainsamples,numbpatten);%为训练样本的特征空间 100*200 %Y2=Getpatten(testsamples,numbpatten);%为测试样本的特征空间 100*200 %% 采用余弦距离分类器进行分类 accu=0; %人脸类别数 mdist=zeros(1,num); for i=1:num for j=1:num if (norm(Y1(:,j))==0||norm(Y2(:,i))==0) return; else mdist(j)=(Y1(:,j)'*Y2(:,i))/(norm(Y1(:,j))*norm(Y2(:,i)));%余弦距离分类器 %mdist(j)=norm( Y1(:,j)- Y2(:,i) ); end end [dist ,index200]=sort(mdist); class=ceil(index200(num)/5); %class=ceil(index200(1)/5); ii=ceil(i/5); if class==ii; accu=accu+1; end end f=accu/num;%%值越大,图像识别率就高,选择的的几率就大 end up4044 4.
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨
🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:人工智能
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙
目录
什么是AIGC?
AIGC的技术原理
1. 神经网络:
2. 深度学习:
3. 自然语言处理(NLP):
4. 生成对抗网络(GANs):
5. 变分自编码器(VAEs):
6. 转移学习(Transfer Learning):
7. 预训练和微调:
8. 注意力机制:
9. 序列到序列模型(Seq2Seq):
10. 强化学习:
AIGC的应用领域
1. 营销和广告
2. 媒体和出版
3. 教育和培训
4. 娱乐和游戏
5. 客户服务
6. 医疗和健康
7. 金融和保险
8. 零售和电商
AIGC的优势和挑战
优势
1. 提高效率
2. 降低成本
3. 个性化定制
挑战
1. 质量控制
2. 伦理和法律问题
3. 技术复杂性
什么是AIGC? 用一句话来说就是用人工智能技术来生成内容
如何使用Python从0训练自己的AI模型 人工智能(AI)是当今科技领域的热门话题之一。在过去的几年里,AI技术在各个领域都取得了重大的突破和应用,例如图像识别、语音识别、自然语言处理等。如果你对AI感兴趣,并且想要亲自动手训练自己的AI模型,那么本篇博客将为你提供一些详细的指导。
思维导图 以下是使用Mermaid代码绘制的思维导图,展示了从0训练自己的AI模型的主要步骤和技术:
确定问题和数据集 数据预处理 构建模型 训练模型 评估和调优模型 部署和应用模型 数据增强 迁移学习 超参数调优 模型部署和应用 以上思维导图清晰地展示了从问题和数据集确定到模型部署和应用的整个过程。通过按照思维导图的指引,你可以一步步地使用Python训练自己的AI模型,并将其用于实际问题的解决。
1. 确定问题和数据集 首先,你需要明确你要解决的问题,并找到合适的数据集来训练你的模型。例如,你可以选择图像分类、情感分析、文本生成等不同的任务。在选择数据集时,要确保数据集的质量和适用性,以便训练出高质量的模型。
2. 数据预处理 在开始训练模型之前,通常需要对数据进行预处理。这包括数据清洗、特征提取和数据转换等步骤。例如,对于图像分类任务,你可能需要将图像转换为数字矩阵,并对图像进行缩放和标准化处理。
以下是一个简单的Python代码示例,展示了如何使用OpenCV库对图像预处理:
import2 def preprocess_image(image): gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) resized_image = cv2.resize(gray_image, (32, 32)) normalized_image = resized_image / 255.0 return normalized_image 3. 构建模型 接下来,你需要选择适合你问题的模型架构,并使用Python构建模型。Python中有许多流行的机器学习库,例如TensorFlow、PyTorch和Scikit-learn,可以帮助你构建和训练模型。
以下是一个简单的Python代码示例,展示了如何使用TensorFlow库构建一个简单的卷积神经网络(CNN)模型:
import tensorflow as tf def build_model(): model = tf.keras.Sequential([ tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 1)), tf.keras.layers.MaxPooling2D((2, 2)), tf.keras.layers.Flatten(), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) return model 4.
关注小庄 顿顿解馋(●’◡’●)
上篇回顾
我们上篇学习了本质为数组的数据结构—顺序表,顺序表支持下标随机访问而且高速缓存命中率高,然而可能造成空间的浪费,同时增加数据时多次移动会造成效率低下,那有什么解决之法呢?这就得引入我们链表这种数据结构
文章目录 一.何为链表🏠 链表概念🏠 链表的分类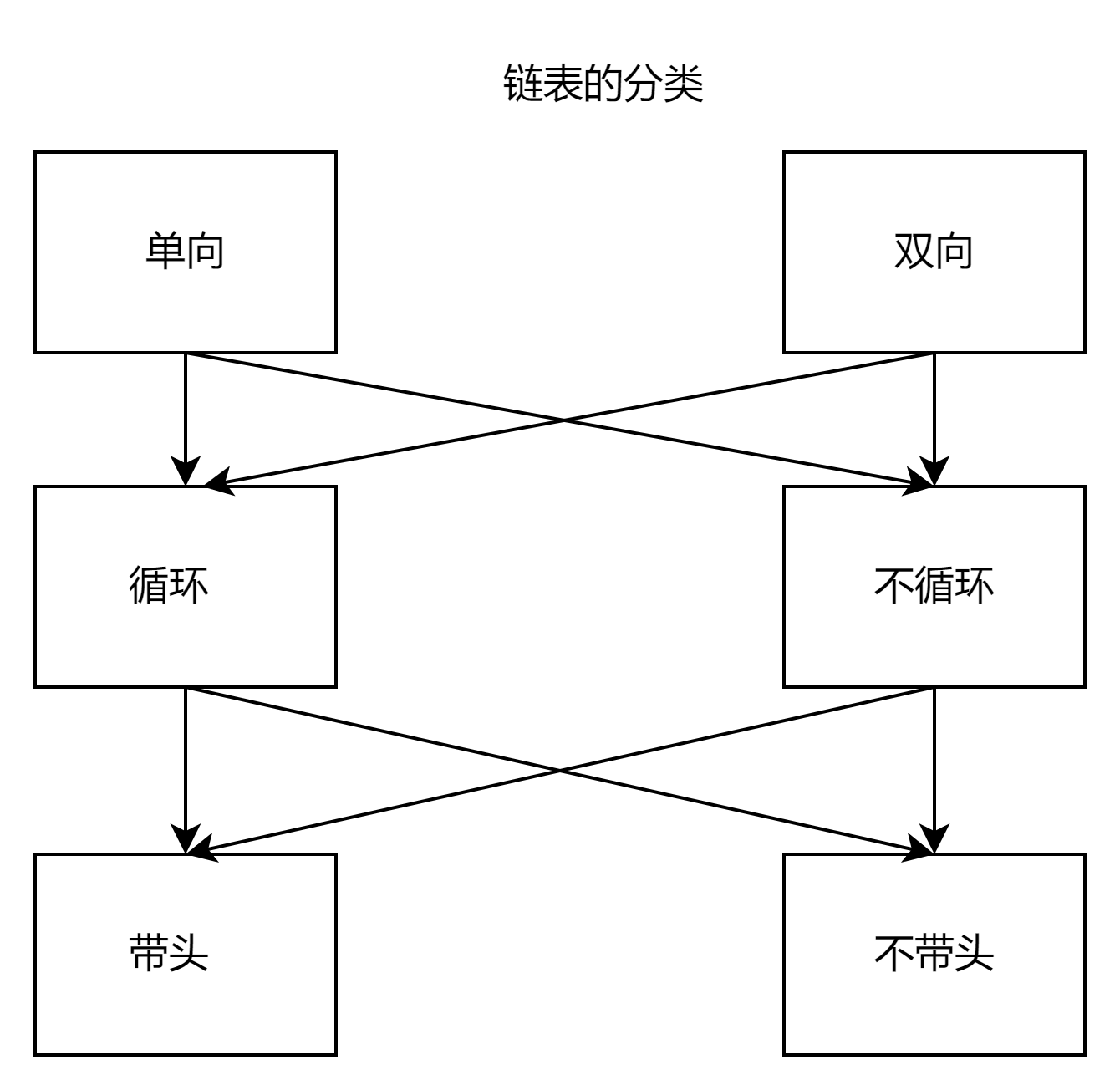 二.单链表的实现🏠 链表的打印🏠 链表的头插和尾插🏠 链表的尾删和头删🏠 链表指定位置的插入和删除🏠 链表的查找🏠 链表的销毁`注: 这里要保存好下一个结点地址,销毁后就能继续遍历` 三.单链表的分析以及与顺序表的比较🏠 单链表的优缺点🏠 单链表与顺序表的比较 一.何为链表 🏠 链表概念 概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表
中的指针链接次序实现的 。
特点:物理结构不一定连续,逻辑结构连续
我们的链表结构类似我们的火车,有头有尾,中间每个结点被有序链接;与火车不同的是,链表的结点可能不是紧挨着的。
类似这样,我们可以得出:
1.每个结点由数据和下一结点地址两部分组成,而每个结点构成了一个链表。
2.每个结点保存的是下一个结点的地址,这样就能找到下一个结点,最后为空就停止
3.每个结点的地址不是连续的,可以体现出链表的物理结构不一定连续
注:我们的结点一般是在堆区开辟的,因为此时你在程序结束前不free就会一直存在这块空间,同时可根据需要灵活申请结点存数据。
这样我们就可以用一个结构体封装每个结点:
typedef int Datatype; typedef struct ListNode { Datatype x; struct ListNode* next; }Node; 注: 这里我们可以用typedef来重命名我们要存储的数据类型,这样对于不同数据的操作我们只要改typedef即可。
🏠 链表的分类 我们根据链表三个特点:1.带头不带头 2.单向还是双向 3.循环还是不循环 组合成了如上的8种链表
本篇博客,我们要实现的是单向不带头不循环链表(单链表),至于什么是带头,双向,循环我们下回双链表再进行讲解
二.单链表的实现 无头+单向+不循环链表的增删差改
🏠 链表的打印 链表数据的打印 这个接口就很好的体现了结点结构保存指针的妙处了~
//链表的打印 void SLTPrint(Node* phead) { asser(phead); Node* cur = phead; while (cur) { printf("
简介 SSA是一种近几年新兴的时序分析算法,通过对时间序列进行升维后做SVD,进而分组重构来实现对时间序列的成分分析,目前用于预测、插值补全以及去噪 具体步骤包括四个部分:
1.构建轨迹矩阵(Embedding) 2.轨迹矩阵SVD分解 3.分组 4.对角平均
1.准备工作 这里我们生成一组间隔带有噪声的序列,包含了周期项、趋势项和随机噪声
import numpy as np import matplotlib.pyplot as plt number = 30 days = 180 tend_sequence = np.linspace(2,-2,num=days) time = np.linspace(0,2*np.pi*days/number,num=days) sin_sequence = np.sin(time) signal = sin_sequence+tend_sequence noise = np.random.randn(days) sequence = noise+sin_sequence+tend_sequence plt.plot(tend_sequence,color='yellow',label='Tendency') plt.plot(sin_sequence,color='blue',label='Periodicity') plt.plot(noise,color='red',label='noise') plt.legend() plt.show() plt.plot(sequence,color='red',label='with noise') plt.plot(signal,color='blue',label='original') plt.legend() plt.show() 2.SSA具体实现 在实际操作中,我们将从以下步骤进行计算: 1. 对于长度为 N N N 的时间序列,以 L L L 为滑动窗口,依次进行采样,获得大小为 L × K L×K L×K 的轨迹矩阵 X X X,其中 K = N − L + 1 K=N-L+1 K=N−L+1 2.